It was my pleasure last week to deliver a mini-workshop at the Independent Schools of New Zealand Annual Conference in Auckland. Intended to be more dialogue than monologue, I’m not sure if it landed quite where I had hoped. It is an exciting time to be thinking about educational governance and my key message was ‘don’t get caught up in the hype’.
Understanding media representations of “Artificial Intelligence”.
Mapping types of AI in 2023
We need to be wary of the hype around the term AI, Artificial Intelligence. I do not believe there is such a thing. Certainly not in the sense the popular press purport it to exist, or has deemed to have sprouted into existence with the advent of ChatGPT. What there is, is a clear exponential increase in the capabilities being demonstrated by computation algorithms. The computational capabilities do not represent intelligence in the sense of sapience or sentience. These capabilities are not informed by the senses derived from an organic nervous system. However, as we perceive these systems to mimic human behaviour, it is important to remember that they are machines.
This does not negate the criticisms of those researchers who argue that there is an existential risk to humanity if A.I. is allowed to continue to grow unchecked in its capabilities. The language in this debate presents a challenge too. We need to acknowledge that intelligence means something different to the neuroscientist and the philosopher, and between the psychologist and the social anthropologist. These semiotic discrepancies become unbreachable when we start to talk about consciousness.
In my view, there are no current Theory of Mind applications… yet. Sophia (Hanson Robotics) is designed to emulate human responses, but it does not display either sapience or sentience.
What we are seeing, in 2023, is the extension of both the ‘memory’, or scope of data inputs, into larger and larger multi-modal language models, which are programmed to see everything as language. The emergence of these polyglot super-savants is remarkable, and we are witnessing the unplanned and (in my view) cavalier mass deployment of these tools.
Ethical spheres for Governing Boards to reflect on in 2023
Ethical and Moral Implications
Educational governing bodies need to stay abreast of the societal impacts of Artificial Intelligence systems as they become more pervasive. This is more important than having a detailed understanding of the underlying technologies or the way each school’s management decides to establish policies. Boards are required to ensure such policies are in place, are realistic, can be monitored, and are reported on.
Policies should already exist around the use of technology in supporting learning and teaching, and these can, and should, be reviewed to ensure they stay current. There are also policy implications for admissions and recruitment, selection processes (both of staff and students) and where A.I. is being used, Boards need to ensure that wherever possible no systemic bias is evident. I believe Boards would benefit from devising their own scenarios and discussing them periodically.
Each month, CUPA-HR General Counsel Ira Shepard provides an overview of several labor and employment law cases and regulatory actions with implications for the higher ed workplace. Here’s the latest from Ira.
Unionization Increases to Record Levels, Largely Driven by Graduate Students and Medical Interns
Unionization in the first six months of 2023 reached near record levels, surpassing last year’s numbers, which were driven by Starbucks employees’ organization drives. In the first six months of 2023, over 58,000 new workers were unionized, almost 15,000 more than last year’s significant levels. The size of new bargaining units has grown, with new units of 500 or more employees growing by 59% over last year. In the first six months of 2023, unions won 95% of elections in large units of over 500 employees compared to 84% in the first six months of 2022.
According to a Bloomberg Law report, this increase coincides with a growth in graduate assistant and medical intern organizing. There have been union organization elections in 17 units involving graduate students and medical interns in the first six months of 2023. This is the highest level of activity in the sector since the 1990s.
Court of Appeals Rejects Religious Discrimination Claim by Fire Chief Who Was Terminated After Attending a Religious Event on “City Time”
The 9th U.S. Circuit Court of Appeals (covering Alaska, Arizona, California, Hawaii, Idaho, Montana, Nevada, Oregon and Washington) rejected a former fire chief’s allegation of religious discrimination after he attended a church-sponsored Christian leadership event in place of attending a non-religious leadership training program he was asked to attend (Hittle v. City of Stockton, California (2023 BL 268076, 9th Cir. 22-15485, 8/4/23)). The court concluded that the fire chief’s supervisors were legitimately concerned about the constitutional implications of a city official attending a church-sponsored event.
The fire chief claimed, as evidence of religious discrimination, that city supervisors questioned whether his attendance at the event was part of a “Christian Coalition.” He further alleged that the supervisors questioned whether he was part of a “Christian clique.” The court rejected the fire chief’s arguments that this questioning amounted to religious bias against Christians. The court concluded that the questioning was related to the report they received on his attendance at the church-sponsored event. The court noted that the supervisors did not use derogatory terms to express their own views. The case may be appealed to the Supreme Court, and we will follow developments as they unfold.
University Wins Dismissal of Federal Sex Harassment Lawsuit for Failure of Professor to File a Timely Underlying Charge of Sex Harassment With the EEOC
Pennsylvania State University won a dismissal of a male ex-professor’s federal sex harassment lawsuit alleging a female professor’s intolerable sex harassment forced him to resign. The Federal Court concluded that the male professor never filed a timely charge with the EEOC (Nassry v. Pennsylvania State University (M.D. Pa. 23-cv-00148, 8/8/23)). The plaintiff professor argued he was entitled to equitable tolling of the statute of limitations because he attempted to resolve the matter internally as opposed to “overburdening the EEOC.”
The court commented that while the plaintiff’s conduct was “commendable,” the court was unable to locate any case where a plaintiff was bold enough to offer such a reason to support equitable tolling. The court dismissed the federal case, holding that there was no way to conclude the plaintiff professor was precluded from filing in a timely manner with the EEOC due to inequitable circumstances. The court dismissed the related state claims without prejudice as there was no requirement that the state claims be filed with the EEOC.
Professor’s First Amendment Retaliatory-Discharge Case Over Refusal to Comply With COVID-19 Health Regulations Allowed to Move to Discovery
A former University of Maine marketing professor who was discharged and lost tenure after refusing to comply with COVID-19 health regulations on the ground that they lacked sufficient scientific evidentiary support is allowed to move forward with discovery. The university’s motion to dismiss was denied (Griffin V. University of Maine System (D. Me. No. 2:22-cv-00212, 8/16/23)).
The court held “for now” the professor is allowed to conduct discovery to flush out evidence of whether or not the actions which led to the termination were actually protected free speech. The court concluded that the actual free speech question will be decided after more facts are unearthed.
U.S. Court of Appeals Reverses Employer-Friendly “Ultimate Employment Decision” Restriction on Actionable Title VII Complaints
The 5th U.S. Circuit Court of Appeals (covering Louisiana, Mississippi and Texas) reversed the long standing, 27-year-old precedent restricting Title VII complaints to those only affecting an “ultimate employment decision.” The employer-friendly precedent allowed the courts to dismiss Title VII complaints not rising to the level of promotion, hiring, firing and the like. The 5th Circuit now joins the 6th Circuit (covering Kentucky, Michigan, Ohio and Tennessee) and the D.C. Circuit (covering Washington, D.C.) in holding that a broader range of employment decisions involving discrimination are subject to Title VII jurisdiction.
The 5th Circuit case involved a Texas detention center which had a policy of allowing only male employees to have the weekend off. The 5th Circuit reversed its prior ruling dismissing the case and allowed the case to proceed. This reversed the old “ultimate employment decision” precedent from being the standard as to whether a discrimination case is subject to Title VII jurisdiction.
Union Reps Can Join OSHA Inspectors Under Newly Revised Regulations
The U.S. Department of Labor has proposed revised regulations that would allow union representatives to accompany OSHA inspectors on inspections. The regulations, which were first proposed during the Obama administration, were stalled by an adverse court order and then dropped during the Trump administration.
The proposed rule would drop OSHA’s current reference to safety engineers and industrial hygienists as approved employee reps who could accompany the inspector. The new rule would allow the OSHA inspector to approve any person “reasonably necessary” to the conduct of a site visit. Among the professions that could be approved are attorneys, translators and worker advocacy group reps. The public comment period on these proposed regulations will run through October 30, 2023.
If we can reduce the time it takes to design a course by about 20%, the productivity and quality impacts for organizations that need to build enough courses to strain their budget and resources will gain “huge” benefits.
We should be able to use generative AI to achieve that goal fairly easily without taking ethical risks and without needing to spend massive amounts of time or money.
Beyond the immediate value of ALDA itself, learning the AI techniques we will use—which are more sophisticated than learning to write better ChatGPT prompts but far less involved than trying to build our own ChatGPT—will help the participants learn to accomplish other goals with AI.
In today’s post, I’m going to provide an example of how the AI principles we will learn in the workshop series can be applied to other projects. The example I’ll use is Competency-Based Education (CBE).
Can I please speak to your Chief Competency Officer?
The argument for more practical, career-focused education is clear. We shouldn’t just teach the same dusty old curriculum with knowledge that students can’t put to use. We should prepare them for today’s world. Teach them competencies.
I’m all for it. I’m on board. Count me in. I’m raising my hand.
I just have a few questions:
How many companies are looking at formally defined competencies when evaluating potential employees or conducting performance reviews?
Of those, how many have specifically evaluated catalogs of generic competencies to see how well they fit with the skills their specific job really requires?
Of those, how many regularly check the competencies to make sure they are up-to-date? (For example, how many marketing departments have adopted generative AI prompt engineering competencies in any formal way?)
Of those, how many are actively searching for, identifying, and defining new competency needs as they arise within their own organizations?
The sources I turn to for such information haven’t shown me that these practices are being implemented widely yet. When I read the recent publications on SkillsTech from Northeastern University’s Center for the Future of Higher Education and Talent Strategy (led by Sean Gallagher, my go-to expert on these sorts of changes), I see growing interest in skills-oriented thinking in the workplace with still-immature means for acting on that interest. At the moment, the sector seems to be very focused on building a technological factory for packaging, measuring, and communicating formally defined skills.
But how do we know that those little packages are the ones people actually need on the job, given how quickly skills change and how fluid the need to acquire them can be? I’m not skeptical about the worthiness of the goal. I’m asking whether we are solving the hard problems that are in the way of achieving it.
Let’s make this more personal. I was a philosophy major. I often half-joke that my education prepared me well for a career in anything except philosophy. What were the competencies I learned? I can read, write, argue, think logically, and challenge my own assumptions. I can’t get any more specific or fine-grained than that. I know I learned more specific competencies that have helped me with my career(s). But I can’t tell you what they are. Even ones that I may use regularly.
At the same time, very few of the jobs I have held in the last 30 years existed when I was an undergraduate. I have learned many competencies since then. What are they? Well, let’s see…I know I have a list around here somewhere….
Honestly, I have no idea. I can make up phrases for my LinkedIn profile, but I can’t give you anything remotely close to a full and authentic list of competencies I have acquired in my career. Or even ones I have acquired in the last six months. For example, I know I have acquired competencies related to AI and prompt engineering. But I can’t articulate them in useful detail without more thought and maybe some help from somebody who is trained and experienced at pulling that sort of information out of people.
The University of Virginia already has an AI in Marketing course up on Coursera. In the next six months, Google, OpenAI, and Facebook (among others) will come out with new base models that are substantially more powerful. New tools will spring up. Practices will evolve within marketing departments. Rules will be put in place about using such tools with different marketing outlets. And so, competencies will evolve. How will the university be able to refresh that course fast enough to keep up? Where will they get their information on the latest practices? How can they edit their courses quickly enough to stay relevant?
How can we support true Competency-Based Education if we don’t know which competencies specific humans in specific jobs need today, including competencies that didn’t exist yesterday?
One way for AI to help
Let’s see if we can make our absurdly challenging task of keeping an AI-in-marketing CBE course up-to-date by applying a little AI. We’ll only assume access to tools that are coming on the market now—some of which you may already be using—and ALDA.
Every day I read about new AI capabilities for work. Many of them, interestingly, are designed to capture information and insights that would otherwise be lost. A tool to generate summaries and to-do lists from videoconferences. Another to annotate software code and explain what it does, line-by-line. One that summarizes documents, including long and technical documents, for different audiences. Every day, we generate so much information and witness so many valuable demonstrations of important skills that are just…lost. They happen and then they’re gone. If you’re not there when they happen and you don’t have the context, prior knowledge, and help to learn them, you probably won’t learn from them.
With the AI enhancements that are being added to our productivity tools now, we can increasingly capture that information as it flies by. Zoom, Teams, Slack, and many other tools will transcribe, summarize, and analyze the knowledge in action as real people apply it in their real work.
This is where ALDA comes in. Don’t think of ALDA as a finished, polished, carved-in-stone software application. Think of it as a working example of an application design pattern. It’s a template.
Remember, the first step in the ALDA workflow is a series of questions that the chatbot asks the expert. In other words, it’s a learning design interview. A learning designer would normally conduct an interview with a subject-matter expert to elicit competencies. But in this case, we make use of the transcripts generated by those other AI as a direct capture of the knowledge-in-action that those interviews are designed to tease out.
ALDA will incorporate a technique called “Retrieval-Augmented Generation,” or “RAG.” Rather than relying on—or hallucinating—the generative AI’s own internal knowledge, it can access your document store. It can help the learning designer sift through the work artifacts and identify the AI skills the marketing team had to apply when that group planned and executed their most recent social media campaign, for example.
Using RAG and the documents we’ve captured, we develop a new interview pattern that creates a dialog between the human expert, the distilled expert practices in the document store, and the generative AI (which may be connected to the internet and have its own current knowledge). That dialogue will look a little different from the one we will script in the workshop series. But that’s the point. The script is the scaffolding for the learning design process. The generative AI in ALDA helps us execute that process, drawing on up-to-the-minute information about applied knowledge we’ve captured from subject-matter experts while they were doing their jobs.
Behind the scenes, ALDA has been given examples of what its output should look like. Maybe those examples include well-written competencies, knowledge required to apply those competencies, and examples of those competencies being properly applied. Maybe we even wrap your ALDA examples in a technical format like Rich Skill Descriptors. Now ALDA knows what good output looks like.
That’s the recipe. If you can use AI to get up-to-date information about the competencies you’re teaching and to convert that information into a teachable format, you’ve just created a huge shortcut. You can capture real-time workplace applied knowledge, distill it, and generate the first draft of a teachable skill.
The workplace-university CBE pipeline
Remember my questions early in this post? Read them again and ask yourself whether the workflow I just described could change the answers in the future:
How many companies are looking at formally defined competencies when evaluating potential employees or conducting performance reviews?
Of those, how many have specifically evaluated catalogs of generic competencies to see how well they fit with the skills their specific job really requires?
Of those, how many regularly check the competencies to make sure they are up-to-date? (For example, how many marketing departments have adopted relevant AI prompt engineering competencies in any formal way?)
Of those, how many are actively searching for, identifying, and defining new competency needs as they arise?
With the AI-enabled workflow I described in the previous section, organizations can plausibly identify critical, up-to-date competencies as they are being used by their employees. They can share those competencies with universities, which can create and maintain up-to-date courses and certification programs. The partner organizations can work together to ensure that students and employees have opportunities to learn the latest skills as they are being practiced in the field.
Will this new learning design process be automagic? Nope. Will it give us a robot tutor in the sky that can semi-read our minds? Nuh-uh. The human educators will still have plenty of work to do. But they’ll be performing higher-value work better and faster. The software won’t cost a bazillion dollars, you’ll understand how it works, and you can evolve it as the technology gets better and more reliable.
Machines shouldn’t be the only ones learning
I think I’ve discovered a competency that I’ve learned in the last six months. I’ve learned how to apply simple AI application design concepts such as RAG to develop novel and impactful solutions to business problems. (I’m sure my CBE friends could express this more precisely and usefully than I have.)
In the months between now, when my team finishes building the first iteration of ALDA, and when the ALDA workshop participants finish the series, technology will have progressed. The big AI vendors will have released at least one generation of new, more powerful AI foundation models. New players will come on the scene. New tools will emerge. But RAG, prompt engineering, and the other skills the participants develop will still apply. ALDA itself, which will almost certainly use tools and models that haven’t been released yet, will show how the competencies we learn still apply and how they evolve in a rapidly changing world.
I hope you’ll consider enrolling your team in the ALDA workshop series. The cost, including all source code and artifacts, is $25,000 for the team. You can find an application form and prospectus here. Applications will be open until the workshop is filled. I already have a few participating teams lined up and a handful more that I am talking to.
You also find a downloadable two-page prospectus and an online participation application form here. To contact me for more information, please fill out this form:
In 2022-23, turnover of higher ed employees was the highest in five years. A new report from CUPA-HR explores the issue of higher ed employee retention and the factors that impact retention.
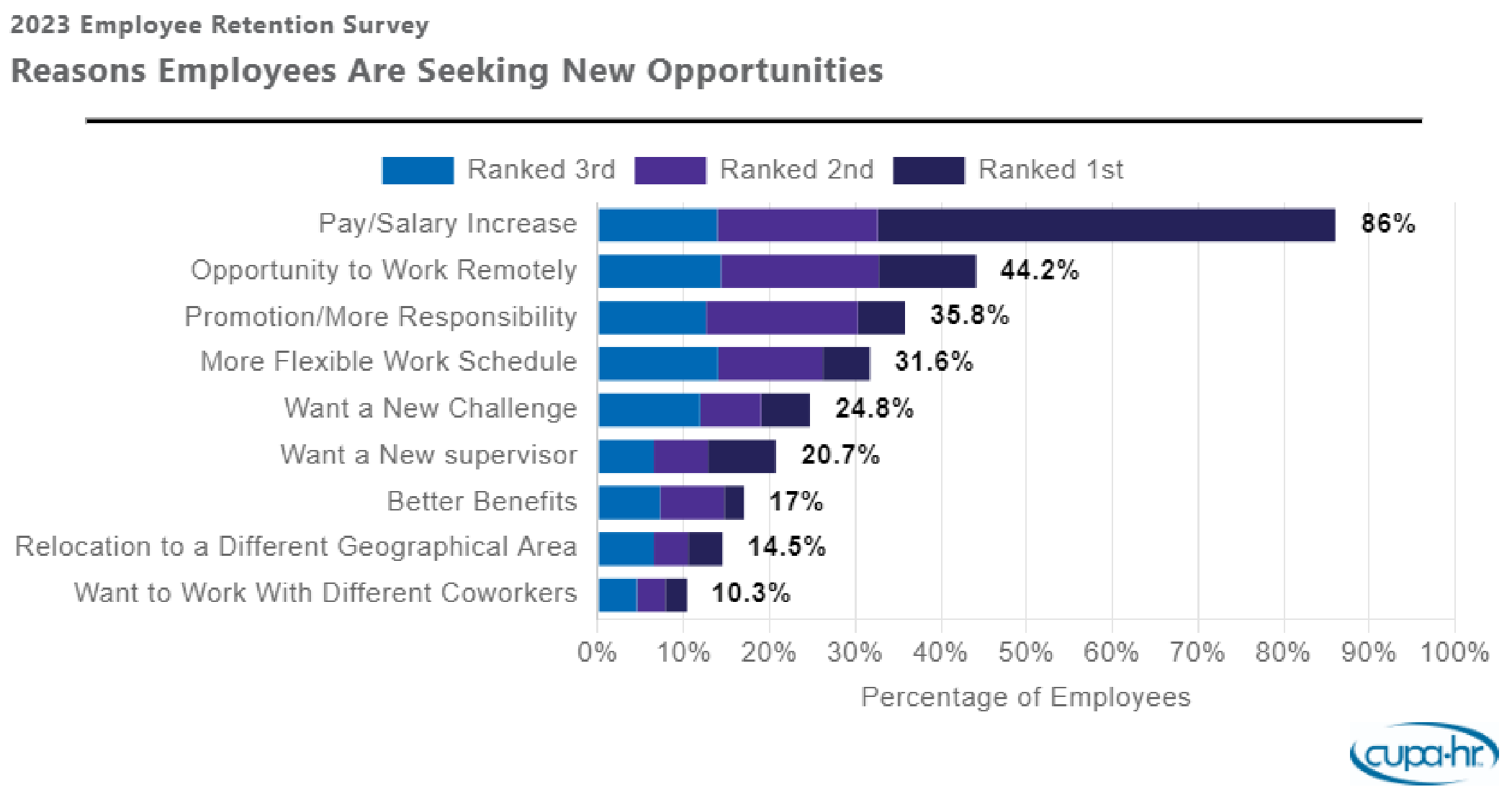
The CUPA-HR 2023 Higher Education Employee Retention Survey analyzed data from 4,782 higher ed employees — administrators, professionals and non-exempt staff, with faculty excluded — from 529 institutions. It found that 33% of higher ed employees surveyed answered they were “very likely” or “likely” to look for new employment opportunities in the next year. More than half (56%) of employees are at least somewhat likely to search for a new job in the coming year.
Top Reasons Higher Ed Employees Are Looking for a New Job
According to the findings, respondents say that pay is the number one reason they’re looking for a new job. Other influential reasons are an opportunity to work remotely, desire for a promotion or more responsibility, and the need for a more flexible work schedule.
But while pay is the top concern mentioned by employees, retention challenges are more complex.
Strongest Predictors of Retention
Digging deeper into the data, the strongest predictors of retention are factors related to job satisfaction and well-being. Only 58% of higher ed employees are generally satisfied with their jobs. Of the 16 aspects of job satisfaction and well-being the survey measured, the three that have the most impact on retention are:
Recognition for Contributions
Being Valued by Others at Work
Having a Sense of Belonging
Only 59% of respondents say they receive regular verbal recognition for doing good work. The good news is that programs, training and policies that increase employee satisfaction in these areas can make a significant impact on retention without necessarily breaking the budget.
Three Things You Can Do
Employees are not necessarily planning to flee higher ed. Most job seekers will be looking within higher ed, and nearly half will be looking within their own institution, indicating that it’s not too late to implement retention strategies. Here are three things you can do to assess and address job satisfaction:
Explore CUPA-HR Resources. Here are several that focus on aspects of job satisfaction:
Plan Next Steps. Share the report or press release with leaders on your campus. Determine areas where your institution could strengthen career development and implement training to increase job satisfaction.
Hi everyone! It’s September and summer and officially over! 🙁
Summer is one of those sacred times of year for faculty to determine the next steps of their faculty career. From my dear colleague who is focused on his retirement to new faculty members who are focused on their new research agenda, everyone is focused on renewal. Our department faculty members usually travel to work at state parks, volunteer in the community, and participate in professional development activities.
This summer, we traveled on a study abroad experience to Scotland, Ireland, and England. This was an incredible journey with 17 students from our university. I have not traveled outside of the country for a year and the students were filled with excitement from the end of the spring semester.
The trip to Europe was long and uneventful. We traveled with EF Tours and it was definitely an adventure. Many of our rural students have never traveled outside of the country before this adventure and they learned many new skills along their journey. I was proud of their progress.
During the study abroad experience, I also had an opportunity walk a mile by myself in Ireland. Previously, I have ALWAYS traveled in groups – large groups and small groups. However, when most of the attendees wanted to participate in an activity together and I had to travel back to the hotel to pick up an item – I had the opportunity be independent. I walked by myself across the city to the hotel. This prepared me for another big adventure that I had this summer. Summer 2023 was filled with solo adventure travel for this female faculty member.
We also had an opportunity to view the Book of Kells in Ireland. It was a great experience and the library that housed the book of Kells (the Bible) was one of the most beautiful libraries I’ve ever visited.
This was my second time to visit the palace in England. There is always a crowd at Buckingham palace and the students enjoyed snapping pictures with the statues.
Who am I kidding? I enjoyed snapping pictures as well! It was crowded and it was definitely an adventure.
I’ve only heard about it on YouTube from flight attendants, but Primark lived up to its reputation. The clothes were inexpensive, high quality, and were gorgeous! I was very excited to buy professor clothes at Primark!
Overall, we had a great time. The students enjoyed themselves and I did as well. I learned a lot about European culture and I added two additional countries to my list. In fact, I added THREE new countries to my list (more about that later). Another day, another post. 😉
Let me know if you have any questions about traveling with students. They are a trip – literally! I cannot remember the last time that I laughed so hard. Traveling with rural students enables them to be themselves while experience a whole new world.
Since February 2007, International Higher Education Consulting Blog has provided timely news and informational pieces, predominately from a U.S. perspective, that are of interest to both the international education and public diplomacy communities. From time to time, International Higher Education Consulting Blog will post thought provoking pieces to challenge readers and to encourage comment and professional dialogue.
Want to build an AI tool that will seriously impact your digital learning program? Right now? For a price that you may well have in your professional development budget?
I’m launching a project to prove we can build a tool that will change the economics of learning design and curricular materials in months rather than years. Its total cost will be low enough to be paid for by workshop participation fees.
Join me.
The learning design bottleneck
Many of my friends running digital course design teams tell me they cannot keep up with demand. Whether their teams are large or small, centralized or instructor-led, higher education or corporate learning and development (L&D), the problem is the same; several friends at large shops have told me that their development of new courses and redesigns of old ones have all but ground to a halt. They don’t have time or money to fix the problem.
I’ve been asking, “Suppose we could accelerate your time to develop a course by, say, 20%?” Twenty percent is my rough, low-end guess about the gains. We should be able to get at least that much benefit without venturing into the more complex and riskier aspects of AI development. “Would a 20% efficiency gain be significant?” I ask.
Answer: “It would be huge.”
My friends tend to cite a few benefits:
Unblocked bottlenecks: A 20% efficiency gain would be enough for them to start building (or rebuilding) courses at a reasonable speed again.
Lower curricular materials costs: Organizations could replace more licensed courses with ones that they own. No more content license costs. And you can edit it any way you need to.
Better quality: The tool would free up learning designers to build better courses rather than running just to get more courses finished.
More flexibility with vendors: Many departments hire custom course design shops. A 20% gain in efficiency would give them more flexibility in deciding when and how to invest their budgets in this kind of consulting.
The learning design bottleneck is a major business problem for many organizations. Relatively modest productivity gains would make a substantial difference for them. Generative AI seems like a good tool for addressing this problem. How hard and expensive would it be to build a tool that, on average, delivers a 20% gain in productivity?
Not very hard, not very expensive
Every LMS vendor, courseware platform provider, curricular materials vendor, and OPM provider is currently working on tools like this. I have talked to a handful of them. They all tell me it’s not hard—depending on your goals. Vendors have two critical constraints. First, the market is highly suspicious of black-box vendor AI and very sensitive to AI products that make mistakes. EdTech companies can’t approach the work as an experiment. Second, they must design their AI features to fit their existing business goals. Every feature competes with other priorities that their clients are asking for.
The project I am launching—AI Learning Design Assistant (ALDA)—is different. First, it’s design/build. The participants will drive the requirements for the software. Second, as I will spell out below, our software development techniques will be relatively simple and easy to understand. In fact, the value of ALDA is as much in learning patterns to build reliable, practical, AI-driven tools as it is in the product itself. And third, the project is safe.
ALDA is intended to produce a first draft for learning designers. No students need to see content that has not been reviewed by a human expert or interact directly with the AI at all. The process by which ALDA produces its draft will be transparent and easy to understand. The output will be editable and importable into the organization’s learning platform of choice.
Here’s how we’ll do it:
Guided prompt engineering: Your learning designers probably already have interview questions for the basic information they need to design a lesson, module, or course. What are the learning goals? How will you know if students have achieved those goals? What are some common sticking points or misconceptions? Who are your students? You may ask more or less specific and more or less elaborate versions of these questions, but you are getting at the same ideas. ALDA will start by interviewing the user, who is the learning designer or subject-matter expert. The structure of the questions will be roughly the same. While we will build out one set of interview questions for the workshop series, changing the design interview protocol should be relatively straightforward for programmers who are not AI specialists.
Long-term memory: One of the challenges with using a tool like ChatGPT on its own is that it can’t remember what you talked about from one conversation to the next and it might or might not remember specific facts that it was trained on (or remember them correctly). We will be adding a long-term memory function. It can remember earlier answers in earlier design sessions. It can look up specific documents you give it to make sure it gets facts right. This is an increasingly common infrastructure component in AI projects. We will explore different uses of it when we build ALDA. You’ll leave the workshop with the knowledge and example code of how to use the technique yourself.
Prompt enrichment: Generative AI often works much better when it has a few really good, rich examples to work from. We will provide ALDA with some high-quality lessons that have been rigorously tested for learning effectiveness over many years. This should increase the quality of ALDA’s first drafts. Again, you may want your learning designs to be different. Since you will have the ALDA source code, you’ll be able to put in whatever examples you want.
Generative AI export: We may or may not get to building this feature depending on the group’s priorities in the time we have, but the same prompt enrichment technique we’ll use to get better learning output can also be used to translate the content into a format that your learning platform of choice can import directly. Our enrichment examples will be marked up in software code. A programmer without any specific AI knowledge can write a handful of examples translating that code format into the one that your platform needs. You can change it, adjust it, and enrich it if you change platforms or if your platform adds new features.
The consistent response from everyone in EdTech I’ve talked to who is doing this kind of work is that we can achieve ALDA’s performance goals with these techniques. If we were trying to get 80% or 90% accuracy, that would be different. But a 20% efficiency gain with an expert human reviewing the output? That should be very much within reach. The main constraints on the ALDA project are time and money. Those are deliberate. Constraints drive focus.
Let’s build something useful. Now.
The collaboration
Teams that want to participate in the workshop will have to apply. I’m recruiting teams that have immediate needs to build content and are willing to contribute their expertise to making ALDA better. There will be no messing around. Participants will be there to build something. For that reason, I’m quite flexible about who is on your team or how many participate. One person is too few, and eight is probably too many. My main criterion is that the people you bring are important to the ALDA-related project you will be working on.
This is critical because we will be designing ALDA together based on the experience and feedback from you and the other participants. In advance of the first workshop, my colleagues and I will review any learning design protocol documentation you care to share and conduct light interviews. Based on that information, you will have access to the first working iteration of ALDA at the first workshop. For this reason, the workshop series will start in the spring. While ALDA isn’t going to require a flux capacitor to work, it will take some know-how and effort to set up.
The workshop cohort will meet virtually once a month after that. Teams will be expected to have used ALDA and come up with feedback and suggestions. I will maintain a rubric for teams to use based on the goals and priorities for the tool as we develop them together. I will take your input to decide which features will be developed in the next iteration. I want each team to finish the workshop series with the conviction that ALDA can achieve those performance gains for some important subset of their course design needs.
Anyone who has been to one of my Empirical Educator Project (EEP) or Blursday Social events knows that I believe that networking and collaboration are undervalued at most events. At each ALDA workshop, you will have time and opportunities to meet with and work with each other. I’d love to have large universities, small colleges, corporate L&D departments, non-profits, and even groups of students participating. I may accept EdTech vendors if and only if they have more to contribute to the group effort than just money. Ideally, the ALDA project will lead to new collaborations, partnerships, and even friendships.
Teaching AI about teaching and learning
The workshop also helps us learn together about how to teach AI about teaching and learning. AI research is showing us how much better the technology can be when it’s trained on good data. There is so much bad pedagogy on the internet. And the content that is good is not marked up in a way that is friendly to teach AI patterns. What does a good learning objective or competency look like? How do you write hints or assessment feedback that helps students learn but doesn’t give away the answers? How do you create alignment among the components of a learning design?
The examples we will be using to teach the AI have not only been fine-tuned for effectiveness using machine learning over many years; they are also semantically coded to capture some of these nuances. These are details that even many course designers haven’t mastered.
I see a lot of folks rushing to build “robot tutors in the sky 2.0” without a lot of care to make sure the machines see what we see as educators. They put a lot of faith in data science but aren’t capturing the right data because they’re ignoring decades of learning science. The ALDA project will teach us how to teach the machines about pedagogy. We will learn to identify the data structures that will empower the next generation of AI-powered learning apps. And we will do that by becoming better teachers of ALDA using the tools of good teaching: clear goals, good instructions, good examples, and good assessments. Much of it will be in plain English, and the rest will be in a simple software markup language that any computer science undergraduate will know.
Wanna play?
The cost for the workshop series, including all source code and artifacts, is $25,000 for your team. You can find an application form and prospectus here. Applications will be open until the workshop is filled. I already have a few participating teams lined up and a handful more that I am talking to.
You also find a downloadable two-page prospectus and an online participation application form here. To contact me for more information, please fill out this form:
[Update: I’m hearing from a couple of you that your messages to me through the form above are getting caught in the spam filter. Feel free to email me at [email protected] if the form isn’t getting through.]
This is a post for folks who want to learn how recent AI developments may affect them as people interested in EdTech who are not necessarily technologists. The tagline of e-Literate is “Present is Prologue.” I try to extrapolate from today’s developments only as far as the evidence takes me with confidence.
Generative AI is the kind of topic that’s a good fit for e-Literate because the conversations about it are fragmented. The academic and technical literature is boiling over with developments on practically a daily basis but is hard for non-technical folks to sift through and follow. The grand syntheses about the future of…well…everything are often written by incredibly smart people who have to make a lot of guesses at a moment of great uncertainty. The business press has important data wrapped in a lot of WHEEEE!
Generative AI will definitely look exactly like this!
Let’s see if we can run this maze, shall we?
Is bigger better?
OpenAI and ChatGPT set many assumptions and expectations about generative AI, starting with the idea that these models must be huge and expensive. Which, in turn, means that only a few tech giants can afford to play.
Right now there are five widely known giants. (Well, six, really, but we’ll get to the surprise contender in a bit.) OpenAI’s ChatGPT and Anthropic’s Claude are pure plays created by start-ups. OpenAI started the whole generative AI craze by showing the world how much anyone who can write English can accomplish with ChatGPT. Anthropic has made a bet on “ethical AI” with more protections from harmful output and a few differentiating features that are important for certain applications but that I’m not going to go into here.
Then there are the big three SaaS hosting giants. Microsoft has been tied very tightly to OpenAI, of which it owns a 49% stake. Google, which has been a pioneering leader in AI technologies but has been a mess with its platforms and products (as usual), has until recently focused on promoting several of its own models. Amazon, which has been late out of the gate, has its own Titan generative AI model that almost nobody has seen yet. But Amazon seems to be coming out of the gate with a strategy that emphasizes hosting an ecosystem of platforms, including Anthropic and others.
About that ecosystem thing. A while back, an internal paper called “We Have No Moat, and OpenAI Doesn’t Either.” leaked from Google. It made the argument that so much innovation was happening so quickly in open-source generative AI that the war chests and proprietary technologies of these big companies wouldn’t give them an advantage over the rapid innovation of a large open-source community.
I could easily write a whole long post about the nature of that innovation. For now, I’ll focus on a few key points that should be accessible to everyone. First, it turns out that the big companies with oodles of money and computing power—surprise!—decided to rely on strategies that required oodles of money and computing power. They didn’t spend a lot of time thinking about how to make their models smaller and more efficient. Open-source teams with far more limited budgets quickly demonstrated that they could make huge gains in algorithmic efficiency. The barrier to entry for building a better LLM—money—is dropping fast.
Complementing this first strategy, some open-source teams worked particularly hard to improve data quality, which requires more hard human work and less brute computing force. It turns out that the old adage holds: garbage in, garbage out. Even smaller systems trained on more carefully curated data are less likely to hallucinate and more likely to give high-quality answers.
And third, it turns out that we don’t need giant all-purpose models all the time. Writing software code is a good example of a specialized generative AI task that can be accomplished well with a much smaller, cheaper model using the techniques described above.
The internal Google memo concluded by arguing that “OpenAI doesn’t matter” while cooperating with open source is vital.
That missive was leaked in May. Guess what’s happened since then?
The swarm
Meta had already announced in February that it was releasing an open-source-ish model called Llama. It was only open-source-ish because its license limited it to research use. That was quickly hacked and abused. The academic teams and smaller startups, which were already innovating like crazy, took advantage of the oodles of money and computing power that Meta was able to put into LLama. Unlike the other giants, Meta doesn’t make money by hosting software. They making from content. Commoditizing the generative AI will lead to much more content being generated. Perhaps seeing an opportunity, when Meta released LLama 2 in July, the only unusual restrictions they placed on the open-source license were to prevent big hosting companies like Amazon, Microsoft, and Google from making money off Llama without paying Meta. Anyone smaller than that can use the Llama models for a variety of purposes, including commercial applications. Importantly, LLama 2 is available in a variety of sizes, including one small enough to run on a newer personal computer.
To be clear, OpenAI, Microsoft, Google, Anthropic, and Google are all continuing to develop their proprietary models. That isn’t going away. But at the same time…
Microsoft, despite their expensive continuing love affair with OpenAI, announced support for Llama 2 and has a license (but not announced products that I can find yet) for Databricks’ open-source Dolly 2.0.
Amazon now supports a growing range of LLMs, including open-source Stability AI and Llama 2.
IBM—’member them?—is back in the AI game, trying to rehabilitate its image after the much-hyped and mostly underwhelming Watson products. The company is trotting out watsonx (with the very now, very wow lower-case “w” at the beginning of the name and “x” at the end) integrated with HuggingFace, which you can think of as being a little bit like the Github for open-source generative AI.
It seems that the Google memo about no moats, which was largely shrugged off publicly way back in May, was taken seriously privately by the major players. All the big companies have been hedging their bets and increasingly investing in making the use of any given LLM easier rather than betting that they can build the One LLM to Rule Them All.
Meanwhile, new specialized and generalized LLMs pop up weekly. For personal use, I bounce between ChatGPT, BingChat, Bard, and Claude, each for different types of tasks (and sometimes a couple at once to compare results). I use DALL-E and Stable Diffusion for image generation. (Midjourney seems great but trying to use it through Discord makes my eyes bleed.) I’ll try the largest Llama 2 model and others when I have easy access to them (which I predict will be soon). I want to put a smaller coding LLM on my laptop, not to have it write programs for me but to have it teach me how to read them.
The most obvious possible end result of this rapid sprawling growth of supported models is that, far from being the singular Big Tech miracle that ChatGPT sold us on with their sudden and bold entrance onto the world stage, generative AI is going to become just one more part of IT stack, albeit a very important one. There will be competition. There will be specialization. The big cloud hosting companies may end up distinguishing themselves not so much by being the first to build Skynet as by their ability to make it easier for technologists to integrate this new and strange toolkit into their development and operations. Meanwhile, a parallel world of alternatives for startups and small or specialized use will spring up.
We have not reached the singularity yet
Meanwhile, that welter of weekly announcements about AI advancements I mentioned before have not included massive breakthroughs in super-intelligent machines. Instead, many of them have been about supporting more models and making them easier to use for real-world development. For example, OpenAI is making a big deal out of how much better ChatGPT Enterprise is at keeping the things you tell it private.
Oh. That would be nice.
I don’t mean to mock the OpenAI folks. This is new tech. Years of effort will need to be invested into making this technology easy and reliable for the uses it’s being put to now. ChatGPT has largely been a very impressive demo as an enterprise application, while ChatGPT Enterprise is exactly what it sounds like; an effort to make ChatgGPT usable in the enterprise.
The folks I talk to who are undertaking ambitious generative AI projects, including ones whose technical expertise I trust a great deal, are telling me they are struggling. The tech is unpredictable. That’s not surprising; generative AI is probabilistic. The same function that enables it to produce novel content also enables it to make up facts. Try QA testing an application like that and avoiding regressions—i.e., bugs you thought you fixed but came back in the next version—using technology like that. Meanwhile, the toolchain around developing, testing, and maintaining generative AI-based software is still very immature.
These problems will be solved. But if the past six months have taught us anything, it’s that our ability to predict the twists and turns ahead is very limited at the moment. Last September, I wrote a piece called “The Miracle, the Grind, and the Wall.” It’s easy to produce miraculous-seeming one-off results with generative AI but often very hard to achieve them reliably at scale. And sometimes we hit walls that prevent us from reaching goals for reasons that we don’t see coming. For example, what happens when you run a data set that has some very subtle problems with it through a probabilistic model with half a trillion computing units, each potentially doing something with the data that is impacted by the problems and passing the modified problematic data onto other parts of the system? How do you trace and fix those “bugs” (if you even call them that).
It’s fun to think about where all of this AI stuff could go. And it’s important to try. But personally, I find the here-and-now to be fun and useful to think about. I can make some reasonable guesses about what might happen in the next 12 months. I can see major changes and improvements AI can contribute to education today that minimize the risk of the grind and the wall. And I can see how to build a curriculum of real-world projects that teaches me and others about the evolving landscape even as we make useful improvements today.
What I’m watching for
Given all that, what am I paying attention to?
Continued frantic scrambling among the big tech players: If you’re not able to read and make sense of the weekly announcements, papers, and new open-source projects, pay attention to Microsoft, Amazon, Google, IBM, OpenAI, Anthropic, and HuggingFace. The four traditional giants in particular seem to be thrashing a bit. They’re all tracking the developments that you and I can’t and are trying to keep up. I’m watching these companies with a critical eye. They’re not leading (yet). They’re running for their lives. They’re in a race. But they don’t know what kind of race it is or which direction to go to reach the finish line. Since these are obviously extremely smart people trying very hard to compete, the cracks and changes in their strategies tell us as much as the strategies themselves.
Practical, short-term implementations in EdTech: I’m not tracking grand AI EdTech moonshot announcements closely. It’s not that they’re unimportant. It’s that I can’t tell from a distance whose work is interesting and don’t have time to chase every project down. Some of them will pan out. Most won’t. And a lot of them are way too far out over their skis. I’ll wait to see who actually gets traction. And by “traction,” I don’t mean grant money or press. I mean real-world accomplishments and adoptions.
On the other hand, people who are deploying AI projects now are learning. I don’t worry too much about what they’re building, since a lot of what they do will be either wrong, uninteresting, or both. Clay Shirky once said the purpose of the first version of software isn’t to find out if you got it right; it’s to learn what you got wrong. (I’m paraphrasing since I can’t find the original quote.) I want to see what people are learning. The short-term projects that are interesting to me are the experiments that can teach us something useful.
The tech being used along with LLMs: ChatGPT did us a disservice by convincing us that it could soon become an all-knowing, hyper-intelligent being. It’s hard to become the all-powerful AI if you can’t reliably perform arithmetic, are prone to hallucinations, can’t remember anything from one conversation to the next, and start to space out if a conversation runs too long. We are being given the impression that the models will eventually get good enough that all these problems will go away. Maybe. For the foreseeable future, we’re better off thinking about them as interfaces with other kinds of software that are better at math, remembering, and so on. “AI” isn’t a monolith. One of the reasons I want to watch short-term projects is that I want to see what other pieces are needed to realize particular goals. For example, start listening for the term “vector database.” The larger tech ecosystem will help define the possibility space.
Intellectual property questions: What happens if The New York Times successfully sues OpenAI for copyright infringement? It’s not like OpenAI can just go into ChatGPT and delete all of those articles. If intellectual property law forces changes to AI training, then the existing models will have big problems (though some have been more careful than others). A chorus of AI cheerleaders tell us, “No, that won’t happen. It’s covered by fair use.” That’s plausible. But are we sure? Are we sure it’s covered in Europe as well as the US? How much should one bet on it? Many subtle legal questions will need to be sorted over the coming several years. The outcomes of various cases will also shape the landscape.
Microchip shortages: This is a weird thing for me to find myself thinking about, but these large generative AI applications—especially training them—run on giant, expensive GPUs. One company, NVidia, has far and away the best processors for this work. So much so that there is a major race on to acquire as many NVidia processors as possible due to limited supply and unlimited demand. And unlike software, a challenger company can’t shock the world with a new microprocessor that changes the world overnight. Designing and fabricating new chips at scale takes years. More than two. Nvidia will be the leader for a long time. Therefore, the ability for AI to grow will be, in some respects, constrained by the company’s production capacity. Don’t believe me? Check out their five-year stock price and note the point when generative AI hype really took off.
AI on my laptop: On the other end of the scale, remember that open-source has been shrinking the size of effective LLMs. For example, Apple has already optimized a version of Stable Diffusion for their operating system and released an open-source one-click installer for easier consumer use. The next step one can imagine is for them to optimize their computer chip—either the soon-to-be-released M3 or the M4 after it. (As I said, computer chips take time.) But one can easily imagine image generation, software code generation, and a chatbot that understands and can talk about the documents you have on your hard drive. All running locally and privately. In the meantime, I’ll be running a few experiments with AI on my laptop. I’ll let you know how it goes.
Present is prologue
Particularly at this moment of great uncertainty and rapid change, it pays to keep your eyes on where you’re walking. A lot of institutions I talk to either are engaged in 57 different AI projects, some of which are incredibly ambitious, or are looking longingly for one thing they can try. I’ll have an announcement on the latter possibility very shortly (which will still work for folks in the former situation). Think about these early efforts as CBE for the future work. The thing about the future is that there’s always more of it. Whatever the future of work is today will be the present of work tomorrow. But there will still be a future of work tomorrow. So we need to build a continuous curriculum of project-based learning with our AI efforts. And we need to watch what’s happening now.
Every day is a surprise. Isn’t that refreshing after decades in EdTech?
On August 30, the Department of Labor (DOL) announced a new proposed update to the salary threshold for the “white collar” exemptions to the Fair Labor Standards Act’s (FLSA) overtime pay requirements.
DOL proposes raising the minimum salary threshold from its current level of $35,568 annually to $55,068 — a nearly 55% increase. It also raises the salary level for the Highly Compensated Exemption (HCE) to $143,988 from its current level of $107,432 (a 34% increase). The proposal does not make any changes to the duties requirements. DOL does, however, propose automatically updating the threshold every three years by tying the threshold to the 35th percentile of weekly earnings of full-time salaried workers in the lowest-wage Census Region. For more information, DOL issued a FAQ document addressing the changes in the proposed rule.
DOL first announced their intention to move forward with the proposal in the Fall 2021 Regulatory Agenda and set a target date for its release in April 2022. However, CUPA-HR, along with other higher education organizations and hundreds of concerned stakeholders, expressed concerns with the timing of the rulemaking and encouraged DOL to hold stakeholder meetings prior to releasing the anticipated overtime Notice of Proposed Rulemaking (NPRM). In a recent letter, CUPA-HR joined other associations in calling for the department to postpone or abandon the anticipated overtime rulemaking, citing concerns with supply chain disruptions, workforce shortages, inflation, and shifting workplace dynamics.
The proposed rule was published in the Federal Register on September 8, allowing the public 60 days to submit comments. CUPA-HR plans to file an extension request with the agency. We will also continue evaluating the current proposal and work with members to prepare comments to submit on behalf of the higher education community. Furthermore, an extended session of the CUPA-HR Washington Update on September 21 will delve into the nuances of these proposed changes and their ramifications on campus.
On August 7, the Equal Employment Opportunity Commission (EEOC) issued a proposed rule to implement the Pregnant Workers Fairness Act (PWFA). The proposed rule provides a framework for how the EEOC plans to enforce protections granted to pregnant workers under the PWFA.
In December, the PWFA wassigned into law through the Consolidated Appropriations Act of 2023. The law establishes employer obligations to provide reasonable accommodations to pregnant employees so long as such accommodations do not cause an undue hardship on the business, and makes it unlawful to take adverse action against a qualified employee requesting or using such reasonable accommodations. The requirements of the law apply only to businesses with 15 or more employees.
Purpose and Definitions
Under the proposed rule, the EEOC states that employers are required to “provide reasonable accommodations to a qualified employee’s or applicant’s known limitation related to, affected by, or arising out of pregnancy, childbirth, or related medical conditions, unless the accommodation will cause an undue hardship on the operation of the business of the covered entity.”
Most definitions included in the EEOC’s proposed regulations follow the definitions provided under the Americans with Disabilities Act (ADA). The proposed rule, however, expands upon the definition of a “qualified employee or applicant” to include an employee or applicant who cannot perform an essential function of the job so long as they meet the following criteria:
Any inability to perform an essential function is for a temporary period
The essential function could be performed in the near future
The inability to perform the essential function can be reasonably accommodated
The rule continues by defining “temporary” as the need to suspend one or more essential functions if “lasting for a limited time, not permanent, and may extend beyond ‘in the near future.’” Accordingly, “in the near future” is defined to extend to 40 weeks from the start of the temporary suspension of an essential function.
Additionally, the terms “pregnancy, childbirth, or related medical conditions” include a non-exhaustive list of examples of conditions that fall within the statute, including current or past pregnancy, potential pregnancy, lactation, use of birth control, menstruation, infertility and fertility treatments, endometriosis, miscarriage, stillbirth, and having or choosing not to have an abortion. The proposed rule specifies that employees and applicants do not have to specify the condition on the list or use medical terms to describe a condition to receive an accommodation.
Reasonable Accommodations
The proposed rule states that requests for an accommodation should both identify the limitation and indicate the need for an adjustment or change at work. The rule adopts the interactive process for approving and adopting reasonable accommodations for employees or applicants as implemented under the ADA, meaning employers and the qualified employee or applicant can work together to reach an agreement on an appropriate accommodation.
The proposed rule also offers a non-exhaustive list of examples of reasonable accommodations that may be agreed upon during the interactive process. These include frequent breaks, schedule changes, paid and unpaid leave, parking accommodations, modifying the work environment to make existing facilities accessible, job restructuring and other examples.
Additionally, the proposed rule introduces “simple modifications,” which are presumed to be reasonable accommodations that do not impose an undue burden in almost all cases. The four simple modifications proposed are:
Allowing employees to carry water and drink, as needed, in the work area
Allowing employees additional restroom breaks
Allowing employees to sit or stand when needed
Allowing employees breaks, as needed, to eat and drink
Supporting Documentation
The proposed rule states that covered employers are not required to seek documentation to prove the medical condition or approve an accommodation, further stating that the employer can only request documentation if it is reasonable in order to determine whether to grant an accommodation for the employee or applicant in question. Under the regulations, “reasonable documentation” is that which describes or confirms the physical condition; that it is related to, affected by, or arising out of pregnancy, childbirth or related medical conditions; and that a change or adjustment at work is needed for that reason. Examples of situations where requesting documentation may be determined to be unreasonable include when the limitation and need for an accommodation are obvious; when the employee has already provided sufficient documentation; when the accommodation is one of the four “simple modifications”; and when the accommodation is needed for lactation.
Remedies and Enforcement
The proposed rule establishes the applicable enforcement mechanisms and remedies available to employees and others covered by Title VII of the Civil Rights Act of 1964 for qualified employees and applicants covered under the PWFA. The rule also proposes several anti-retaliation and anti-coercion provisions to the list of protections granted to those covered by the PWFA.
Next Steps
The EEOC’s proposed rule marks the agency’s first step toward finalizing PWFA regulations. Although the timing is uncertain, the EEOC will likely aim to issue the final regulations by December 29 — the deadline Congress gave the agency to finalize a rulemaking to implement the law. Notably, however, the PWFA went into effect on June 27, meaning the EEOC is now accepting violation charges stemming from PWFA violations without having a final rule implemented.
The EEOC invites interested stakeholders to submit comments in response to the proposed rule by October 11. Comments will be considered by the agency before issuing its final rule for the PWFA.
CUPA-HR will keep members apprised of any activity relating to the PWFA regulations.


 Ethical spheres for Governing Boards to reflect on in 2023
Ethical spheres for Governing Boards to reflect on in 2023



 But while pay is the top concern mentioned by employees, retention challenges are more complex.
But while pay is the top concern mentioned by employees, retention challenges are more complex.














{kind=link}
{kind=link}
{kind=link}
{kind=link}