Want to build an AI tool that will seriously impact your digital learning program? Right now? For a price that you may well have in your professional development budget?
I’m launching a project to prove we can build a tool that will change the economics of learning design and curricular materials in months rather than years. Its total cost will be low enough to be paid for by workshop participation fees.
Join me.
The learning design bottleneck
Many of my friends running digital course design teams tell me they cannot keep up with demand. Whether their teams are large or small, centralized or instructor-led, higher education or corporate learning and development (L&D), the problem is the same; several friends at large shops have told me that their development of new courses and redesigns of old ones have all but ground to a halt. They don’t have time or money to fix the problem.
I’ve been asking, “Suppose we could accelerate your time to develop a course by, say, 20%?” Twenty percent is my rough, low-end guess about the gains. We should be able to get at least that much benefit without venturing into the more complex and riskier aspects of AI development. “Would a 20% efficiency gain be significant?” I ask.
Answer: “It would be huge.”
My friends tend to cite a few benefits:
Unblocked bottlenecks: A 20% efficiency gain would be enough for them to start building (or rebuilding) courses at a reasonable speed again.
Lower curricular materials costs: Organizations could replace more licensed courses with ones that they own. No more content license costs. And you can edit it any way you need to.
Better quality: The tool would free up learning designers to build better courses rather than running just to get more courses finished.
More flexibility with vendors: Many departments hire custom course design shops. A 20% gain in efficiency would give them more flexibility in deciding when and how to invest their budgets in this kind of consulting.
The learning design bottleneck is a major business problem for many organizations. Relatively modest productivity gains would make a substantial difference for them. Generative AI seems like a good tool for addressing this problem. How hard and expensive would it be to build a tool that, on average, delivers a 20% gain in productivity?
Not very hard, not very expensive
Every LMS vendor, courseware platform provider, curricular materials vendor, and OPM provider is currently working on tools like this. I have talked to a handful of them. They all tell me it’s not hard—depending on your goals. Vendors have two critical constraints. First, the market is highly suspicious of black-box vendor AI and very sensitive to AI products that make mistakes. EdTech companies can’t approach the work as an experiment. Second, they must design their AI features to fit their existing business goals. Every feature competes with other priorities that their clients are asking for.
The project I am launching—AI Learning Design Assistant (ALDA)—is different. First, it’s design/build. The participants will drive the requirements for the software. Second, as I will spell out below, our software development techniques will be relatively simple and easy to understand. In fact, the value of ALDA is as much in learning patterns to build reliable, practical, AI-driven tools as it is in the product itself. And third, the project is safe.
ALDA is intended to produce a first draft for learning designers. No students need to see content that has not been reviewed by a human expert or interact directly with the AI at all. The process by which ALDA produces its draft will be transparent and easy to understand. The output will be editable and importable into the organization’s learning platform of choice.
Here’s how we’ll do it:
Guided prompt engineering: Your learning designers probably already have interview questions for the basic information they need to design a lesson, module, or course. What are the learning goals? How will you know if students have achieved those goals? What are some common sticking points or misconceptions? Who are your students? You may ask more or less specific and more or less elaborate versions of these questions, but you are getting at the same ideas. ALDA will start by interviewing the user, who is the learning designer or subject-matter expert. The structure of the questions will be roughly the same. While we will build out one set of interview questions for the workshop series, changing the design interview protocol should be relatively straightforward for programmers who are not AI specialists.
Long-term memory: One of the challenges with using a tool like ChatGPT on its own is that it can’t remember what you talked about from one conversation to the next and it might or might not remember specific facts that it was trained on (or remember them correctly). We will be adding a long-term memory function. It can remember earlier answers in earlier design sessions. It can look up specific documents you give it to make sure it gets facts right. This is an increasingly common infrastructure component in AI projects. We will explore different uses of it when we build ALDA. You’ll leave the workshop with the knowledge and example code of how to use the technique yourself.
Prompt enrichment: Generative AI often works much better when it has a few really good, rich examples to work from. We will provide ALDA with some high-quality lessons that have been rigorously tested for learning effectiveness over many years. This should increase the quality of ALDA’s first drafts. Again, you may want your learning designs to be different. Since you will have the ALDA source code, you’ll be able to put in whatever examples you want.
Generative AI export: We may or may not get to building this feature depending on the group’s priorities in the time we have, but the same prompt enrichment technique we’ll use to get better learning output can also be used to translate the content into a format that your learning platform of choice can import directly. Our enrichment examples will be marked up in software code. A programmer without any specific AI knowledge can write a handful of examples translating that code format into the one that your platform needs. You can change it, adjust it, and enrich it if you change platforms or if your platform adds new features.
The consistent response from everyone in EdTech I’ve talked to who is doing this kind of work is that we can achieve ALDA’s performance goals with these techniques. If we were trying to get 80% or 90% accuracy, that would be different. But a 20% efficiency gain with an expert human reviewing the output? That should be very much within reach. The main constraints on the ALDA project are time and money. Those are deliberate. Constraints drive focus.
Let’s build something useful. Now.
The collaboration
Teams that want to participate in the workshop will have to apply. I’m recruiting teams that have immediate needs to build content and are willing to contribute their expertise to making ALDA better. There will be no messing around. Participants will be there to build something. For that reason, I’m quite flexible about who is on your team or how many participate. One person is too few, and eight is probably too many. My main criterion is that the people you bring are important to the ALDA-related project you will be working on.
This is critical because we will be designing ALDA together based on the experience and feedback from you and the other participants. In advance of the first workshop, my colleagues and I will review any learning design protocol documentation you care to share and conduct light interviews. Based on that information, you will have access to the first working iteration of ALDA at the first workshop. For this reason, the workshop series will start in the spring. While ALDA isn’t going to require a flux capacitor to work, it will take some know-how and effort to set up.
The workshop cohort will meet virtually once a month after that. Teams will be expected to have used ALDA and come up with feedback and suggestions. I will maintain a rubric for teams to use based on the goals and priorities for the tool as we develop them together. I will take your input to decide which features will be developed in the next iteration. I want each team to finish the workshop series with the conviction that ALDA can achieve those performance gains for some important subset of their course design needs.
Anyone who has been to one of my Empirical Educator Project (EEP) or Blursday Social events knows that I believe that networking and collaboration are undervalued at most events. At each ALDA workshop, you will have time and opportunities to meet with and work with each other. I’d love to have large universities, small colleges, corporate L&D departments, non-profits, and even groups of students participating. I may accept EdTech vendors if and only if they have more to contribute to the group effort than just money. Ideally, the ALDA project will lead to new collaborations, partnerships, and even friendships.
Teaching AI about teaching and learning
The workshop also helps us learn together about how to teach AI about teaching and learning. AI research is showing us how much better the technology can be when it’s trained on good data. There is so much bad pedagogy on the internet. And the content that is good is not marked up in a way that is friendly to teach AI patterns. What does a good learning objective or competency look like? How do you write hints or assessment feedback that helps students learn but doesn’t give away the answers? How do you create alignment among the components of a learning design?
The examples we will be using to teach the AI have not only been fine-tuned for effectiveness using machine learning over many years; they are also semantically coded to capture some of these nuances. These are details that even many course designers haven’t mastered.
I see a lot of folks rushing to build “robot tutors in the sky 2.0” without a lot of care to make sure the machines see what we see as educators. They put a lot of faith in data science but aren’t capturing the right data because they’re ignoring decades of learning science. The ALDA project will teach us how to teach the machines about pedagogy. We will learn to identify the data structures that will empower the next generation of AI-powered learning apps. And we will do that by becoming better teachers of ALDA using the tools of good teaching: clear goals, good instructions, good examples, and good assessments. Much of it will be in plain English, and the rest will be in a simple software markup language that any computer science undergraduate will know.
Wanna play?
The cost for the workshop series, including all source code and artifacts, is $25,000 for your team. You can find an application form and prospectus here. Applications will be open until the workshop is filled. I already have a few participating teams lined up and a handful more that I am talking to.
You also find a downloadable two-page prospectus and an online participation application form here. To contact me for more information, please fill out this form:
[Update: I’m hearing from a couple of you that your messages to me through the form above are getting caught in the spam filter. Feel free to email me at [email protected] if the form isn’t getting through.]
This is a post for folks who want to learn how recent AI developments may affect them as people interested in EdTech who are not necessarily technologists. The tagline of e-Literate is “Present is Prologue.” I try to extrapolate from today’s developments only as far as the evidence takes me with confidence.
Generative AI is the kind of topic that’s a good fit for e-Literate because the conversations about it are fragmented. The academic and technical literature is boiling over with developments on practically a daily basis but is hard for non-technical folks to sift through and follow. The grand syntheses about the future of…well…everything are often written by incredibly smart people who have to make a lot of guesses at a moment of great uncertainty. The business press has important data wrapped in a lot of WHEEEE!
Generative AI will definitely look exactly like this!
Let’s see if we can run this maze, shall we?
Is bigger better?
OpenAI and ChatGPT set many assumptions and expectations about generative AI, starting with the idea that these models must be huge and expensive. Which, in turn, means that only a few tech giants can afford to play.
Right now there are five widely known giants. (Well, six, really, but we’ll get to the surprise contender in a bit.) OpenAI’s ChatGPT and Anthropic’s Claude are pure plays created by start-ups. OpenAI started the whole generative AI craze by showing the world how much anyone who can write English can accomplish with ChatGPT. Anthropic has made a bet on “ethical AI” with more protections from harmful output and a few differentiating features that are important for certain applications but that I’m not going to go into here.
Then there are the big three SaaS hosting giants. Microsoft has been tied very tightly to OpenAI, of which it owns a 49% stake. Google, which has been a pioneering leader in AI technologies but has been a mess with its platforms and products (as usual), has until recently focused on promoting several of its own models. Amazon, which has been late out of the gate, has its own Titan generative AI model that almost nobody has seen yet. But Amazon seems to be coming out of the gate with a strategy that emphasizes hosting an ecosystem of platforms, including Anthropic and others.
About that ecosystem thing. A while back, an internal paper called “We Have No Moat, and OpenAI Doesn’t Either.” leaked from Google. It made the argument that so much innovation was happening so quickly in open-source generative AI that the war chests and proprietary technologies of these big companies wouldn’t give them an advantage over the rapid innovation of a large open-source community.
I could easily write a whole long post about the nature of that innovation. For now, I’ll focus on a few key points that should be accessible to everyone. First, it turns out that the big companies with oodles of money and computing power—surprise!—decided to rely on strategies that required oodles of money and computing power. They didn’t spend a lot of time thinking about how to make their models smaller and more efficient. Open-source teams with far more limited budgets quickly demonstrated that they could make huge gains in algorithmic efficiency. The barrier to entry for building a better LLM—money—is dropping fast.
Complementing this first strategy, some open-source teams worked particularly hard to improve data quality, which requires more hard human work and less brute computing force. It turns out that the old adage holds: garbage in, garbage out. Even smaller systems trained on more carefully curated data are less likely to hallucinate and more likely to give high-quality answers.
And third, it turns out that we don’t need giant all-purpose models all the time. Writing software code is a good example of a specialized generative AI task that can be accomplished well with a much smaller, cheaper model using the techniques described above.
The internal Google memo concluded by arguing that “OpenAI doesn’t matter” while cooperating with open source is vital.
That missive was leaked in May. Guess what’s happened since then?
The swarm
Meta had already announced in February that it was releasing an open-source-ish model called Llama. It was only open-source-ish because its license limited it to research use. That was quickly hacked and abused. The academic teams and smaller startups, which were already innovating like crazy, took advantage of the oodles of money and computing power that Meta was able to put into LLama. Unlike the other giants, Meta doesn’t make money by hosting software. They making from content. Commoditizing the generative AI will lead to much more content being generated. Perhaps seeing an opportunity, when Meta released LLama 2 in July, the only unusual restrictions they placed on the open-source license were to prevent big hosting companies like Amazon, Microsoft, and Google from making money off Llama without paying Meta. Anyone smaller than that can use the Llama models for a variety of purposes, including commercial applications. Importantly, LLama 2 is available in a variety of sizes, including one small enough to run on a newer personal computer.
To be clear, OpenAI, Microsoft, Google, Anthropic, and Google are all continuing to develop their proprietary models. That isn’t going away. But at the same time…
Microsoft, despite their expensive continuing love affair with OpenAI, announced support for Llama 2 and has a license (but not announced products that I can find yet) for Databricks’ open-source Dolly 2.0.
Amazon now supports a growing range of LLMs, including open-source Stability AI and Llama 2.
IBM—’member them?—is back in the AI game, trying to rehabilitate its image after the much-hyped and mostly underwhelming Watson products. The company is trotting out watsonx (with the very now, very wow lower-case “w” at the beginning of the name and “x” at the end) integrated with HuggingFace, which you can think of as being a little bit like the Github for open-source generative AI.
It seems that the Google memo about no moats, which was largely shrugged off publicly way back in May, was taken seriously privately by the major players. All the big companies have been hedging their bets and increasingly investing in making the use of any given LLM easier rather than betting that they can build the One LLM to Rule Them All.
Meanwhile, new specialized and generalized LLMs pop up weekly. For personal use, I bounce between ChatGPT, BingChat, Bard, and Claude, each for different types of tasks (and sometimes a couple at once to compare results). I use DALL-E and Stable Diffusion for image generation. (Midjourney seems great but trying to use it through Discord makes my eyes bleed.) I’ll try the largest Llama 2 model and others when I have easy access to them (which I predict will be soon). I want to put a smaller coding LLM on my laptop, not to have it write programs for me but to have it teach me how to read them.
The most obvious possible end result of this rapid sprawling growth of supported models is that, far from being the singular Big Tech miracle that ChatGPT sold us on with their sudden and bold entrance onto the world stage, generative AI is going to become just one more part of IT stack, albeit a very important one. There will be competition. There will be specialization. The big cloud hosting companies may end up distinguishing themselves not so much by being the first to build Skynet as by their ability to make it easier for technologists to integrate this new and strange toolkit into their development and operations. Meanwhile, a parallel world of alternatives for startups and small or specialized use will spring up.
We have not reached the singularity yet
Meanwhile, that welter of weekly announcements about AI advancements I mentioned before have not included massive breakthroughs in super-intelligent machines. Instead, many of them have been about supporting more models and making them easier to use for real-world development. For example, OpenAI is making a big deal out of how much better ChatGPT Enterprise is at keeping the things you tell it private.
Oh. That would be nice.
I don’t mean to mock the OpenAI folks. This is new tech. Years of effort will need to be invested into making this technology easy and reliable for the uses it’s being put to now. ChatGPT has largely been a very impressive demo as an enterprise application, while ChatGPT Enterprise is exactly what it sounds like; an effort to make ChatgGPT usable in the enterprise.
The folks I talk to who are undertaking ambitious generative AI projects, including ones whose technical expertise I trust a great deal, are telling me they are struggling. The tech is unpredictable. That’s not surprising; generative AI is probabilistic. The same function that enables it to produce novel content also enables it to make up facts. Try QA testing an application like that and avoiding regressions—i.e., bugs you thought you fixed but came back in the next version—using technology like that. Meanwhile, the toolchain around developing, testing, and maintaining generative AI-based software is still very immature.
These problems will be solved. But if the past six months have taught us anything, it’s that our ability to predict the twists and turns ahead is very limited at the moment. Last September, I wrote a piece called “The Miracle, the Grind, and the Wall.” It’s easy to produce miraculous-seeming one-off results with generative AI but often very hard to achieve them reliably at scale. And sometimes we hit walls that prevent us from reaching goals for reasons that we don’t see coming. For example, what happens when you run a data set that has some very subtle problems with it through a probabilistic model with half a trillion computing units, each potentially doing something with the data that is impacted by the problems and passing the modified problematic data onto other parts of the system? How do you trace and fix those “bugs” (if you even call them that).
It’s fun to think about where all of this AI stuff could go. And it’s important to try. But personally, I find the here-and-now to be fun and useful to think about. I can make some reasonable guesses about what might happen in the next 12 months. I can see major changes and improvements AI can contribute to education today that minimize the risk of the grind and the wall. And I can see how to build a curriculum of real-world projects that teaches me and others about the evolving landscape even as we make useful improvements today.
What I’m watching for
Given all that, what am I paying attention to?
Continued frantic scrambling among the big tech players: If you’re not able to read and make sense of the weekly announcements, papers, and new open-source projects, pay attention to Microsoft, Amazon, Google, IBM, OpenAI, Anthropic, and HuggingFace. The four traditional giants in particular seem to be thrashing a bit. They’re all tracking the developments that you and I can’t and are trying to keep up. I’m watching these companies with a critical eye. They’re not leading (yet). They’re running for their lives. They’re in a race. But they don’t know what kind of race it is or which direction to go to reach the finish line. Since these are obviously extremely smart people trying very hard to compete, the cracks and changes in their strategies tell us as much as the strategies themselves.
Practical, short-term implementations in EdTech: I’m not tracking grand AI EdTech moonshot announcements closely. It’s not that they’re unimportant. It’s that I can’t tell from a distance whose work is interesting and don’t have time to chase every project down. Some of them will pan out. Most won’t. And a lot of them are way too far out over their skis. I’ll wait to see who actually gets traction. And by “traction,” I don’t mean grant money or press. I mean real-world accomplishments and adoptions.
On the other hand, people who are deploying AI projects now are learning. I don’t worry too much about what they’re building, since a lot of what they do will be either wrong, uninteresting, or both. Clay Shirky once said the purpose of the first version of software isn’t to find out if you got it right; it’s to learn what you got wrong. (I’m paraphrasing since I can’t find the original quote.) I want to see what people are learning. The short-term projects that are interesting to me are the experiments that can teach us something useful.
The tech being used along with LLMs: ChatGPT did us a disservice by convincing us that it could soon become an all-knowing, hyper-intelligent being. It’s hard to become the all-powerful AI if you can’t reliably perform arithmetic, are prone to hallucinations, can’t remember anything from one conversation to the next, and start to space out if a conversation runs too long. We are being given the impression that the models will eventually get good enough that all these problems will go away. Maybe. For the foreseeable future, we’re better off thinking about them as interfaces with other kinds of software that are better at math, remembering, and so on. “AI” isn’t a monolith. One of the reasons I want to watch short-term projects is that I want to see what other pieces are needed to realize particular goals. For example, start listening for the term “vector database.” The larger tech ecosystem will help define the possibility space.
Intellectual property questions: What happens if The New York Times successfully sues OpenAI for copyright infringement? It’s not like OpenAI can just go into ChatGPT and delete all of those articles. If intellectual property law forces changes to AI training, then the existing models will have big problems (though some have been more careful than others). A chorus of AI cheerleaders tell us, “No, that won’t happen. It’s covered by fair use.” That’s plausible. But are we sure? Are we sure it’s covered in Europe as well as the US? How much should one bet on it? Many subtle legal questions will need to be sorted over the coming several years. The outcomes of various cases will also shape the landscape.
Microchip shortages: This is a weird thing for me to find myself thinking about, but these large generative AI applications—especially training them—run on giant, expensive GPUs. One company, NVidia, has far and away the best processors for this work. So much so that there is a major race on to acquire as many NVidia processors as possible due to limited supply and unlimited demand. And unlike software, a challenger company can’t shock the world with a new microprocessor that changes the world overnight. Designing and fabricating new chips at scale takes years. More than two. Nvidia will be the leader for a long time. Therefore, the ability for AI to grow will be, in some respects, constrained by the company’s production capacity. Don’t believe me? Check out their five-year stock price and note the point when generative AI hype really took off.
AI on my laptop: On the other end of the scale, remember that open-source has been shrinking the size of effective LLMs. For example, Apple has already optimized a version of Stable Diffusion for their operating system and released an open-source one-click installer for easier consumer use. The next step one can imagine is for them to optimize their computer chip—either the soon-to-be-released M3 or the M4 after it. (As I said, computer chips take time.) But one can easily imagine image generation, software code generation, and a chatbot that understands and can talk about the documents you have on your hard drive. All running locally and privately. In the meantime, I’ll be running a few experiments with AI on my laptop. I’ll let you know how it goes.
Present is prologue
Particularly at this moment of great uncertainty and rapid change, it pays to keep your eyes on where you’re walking. A lot of institutions I talk to either are engaged in 57 different AI projects, some of which are incredibly ambitious, or are looking longingly for one thing they can try. I’ll have an announcement on the latter possibility very shortly (which will still work for folks in the former situation). Think about these early efforts as CBE for the future work. The thing about the future is that there’s always more of it. Whatever the future of work is today will be the present of work tomorrow. But there will still be a future of work tomorrow. So we need to build a continuous curriculum of project-based learning with our AI efforts. And we need to watch what’s happening now.
Every day is a surprise. Isn’t that refreshing after decades in EdTech?
A friend recently asked me for advice on a problem he was wrestling with related to an issue he was having with a 1EdTech interoperability standard. It was the same old problem of a standard not quite getting true interoperability because people implement it differently. I suggested he try using a generative AI tool to fix his problem. (I’ll explain how shortly.)
I don’t know if my idea will work yet—he promised to let me know once he tries it—but the idea got me thinking. Generative AI probably will change EdTech integration, interoperability, and the impact that interoperability standards can have on learning design. These changes, in turn, impact the roles of developers, standards bodies, and learning designers.
In this post, I’ll provide a series of increasingly ambitious use cases related to the EdTech interoperability work of 1EdTech (formerly known as IMS Global). In each case, I’ll explore how generative could impact similar work going forward, how it changes the purpose of interoperability standards-making, and how it impacts the jobs and skills of various people whose work is touched by the standards in one way or another.
Generative AI as duct tape: fixing QTI
1EdTech’s Question Test Interoperability (QTI) standard is one of its oldest standards that’s still widely used. The earliest version on the 1EdTech website dates back to 2002, while the most recent version was released in 2022. You can guess from the name what it’s supposed to do. If you have a test, or a test question bank, in one LMS, QTI is supposed to let you migrate it into another without copying and pasting. It’s an import/export standard.
It never worked well. Everybody has their own interpretation of the standard, which means that importing somebody else’s QTI export is never seamless. When speaking recently about QTI to a friend at an LMS company, I commented that it only works about 80% of the time. My friend replied, “I think you’re being generous. It probably only works about 40% of the time.” 1EdTech has learned many lessons about achieving consistent interoperability in the decades since QTI was created. But it’s hard to fix a complex legacy standard like this one.
Meanwhile, the friend I mentioned at the top of the post asked me recently about practical advice for dealing with this state of affairs. His organization imports a lot of QTI question banks from multiple sources. So his team spends a lot of time debugging those imports. Is there an easier way?
I thought about it.
“Your developers probably have many examples that they’ve fixed by hand by now. They know the patterns. Take a handful of before and after examples. Embed them into a prompt in a generative AI that’s good at software code, like Hugging Chat. [As I was drafting this post, OpenAI announced that ChatGPT now has a code interpreter.] “Then give the generative AI a novel input and see if it produces the correct output.”
Generative AI are good at pattern matching. The differences in QTI implementations are likely to have patterns to them that an LLM can detect, even if those differences change over time (because, for example, one vendor’s QTI implementation changed over time).
In fact, pattern matching on this scale could work very well with a smaller generative AI model. We’re used to talking about ChatGPT, Google Bard, and other big-name systems that have between half a billion and a billion transformers. Think of transformers as computing legos. One major reason that ChatGPT is so impressive is that it uses a lot of computing legos. Which makes it expensive, slow, and computationally intensive. But if your goal is to match patterns against a set of relatively well-structured set of texts such as QTI files, you could probably train a much smaller model than ChatGPT to reliably translate between implementations for you. The smallest models, like Vicuña LLM, are only 7 billion transformers. That may sound like a lot but it’s small enough to run on a personal computer (or possibly even a mobile phone). Think about it this way: The QTI task we’re trying to solve for is roughly equivalent in complexity to the spell-checking and one-word type-ahead functions that you have on your phone today. A generative AI model for fixing QTI imports could probably be trained for a few hundred dollars and run for pennies.
This use case has some other desirable characteristics. First, it doesn’t have to work at high volume in real time. It can be a batch process. Throw the dirty dishes in the dishwasher, turn it on, and take out the clean dishes when the machine shuts off. Second, the task has no significant security risks and wouldn’t expose any personally identifiable information. Third, nothing terrible happens if the thing gets a conversion wrong every now and then. Maybe the organization would have to fix 5% of the conversions rather than 100%. And overall, it should be relatively cheap. Maybe not as cheap as running an old-fashioned deterministic program that’s optimized for efficiency. But maybe cheap enough to be worth it. Particularly if the organization has to keep adding new and different QTI implementation imports. It might be easier and faster to adjust the model with fine-tuning or prompting than it would be to revise a set of if/then statements in a traditional program.
How would the need for skilled programmers change? Somebody would still need to understand how the QTI mappings work well enough to keep the generative AI humming along. And somebody would have to know how to take care of the AI itself (although that process is getting easier every day, especially for this kind of a use case). The repetitive work they are doing now would be replaced by the software over time, freeing up the human brains for other things that human brains are particularly good at. In other words, you can’t get rid of your programmer but you can have that person engaging in more challenging, high-value work than import bug whack-a-mole.
How does it change the standards-making process? In the short term, I’d argue that 1EdTech should absolutely try to build an open-source generative AI of the type I’m describing rather than trying to fix QTI, which is a task they’ve not succeeded in doing over 20 years. This strikes me as a far shorter path to achieving the original purpose for which QTI was intended, which is to move question banks from one system to another.
This conclusion, in turn, leads to a larger question: Do we need interoperability standards bodies in the age of AI?
My answer is a resounding “yes.”
Going a step further: software integration
QTI provides data portability but not integration. It’s an import/export format. The fact that Google Docs can open up a document exported from Microsoft Word doesn’t mean that the two programs are integrated in any meaningful way.
So let’s consider Learning Tool Interoperability (LTI). LTI was quietly revolutionary. Before it existed, any company building a specialized educational tool would have to write separate integrations for every LMS.
The nature of education is that it’s filled with what folks in the software industry would disparagingly call “point solutions.” If you’re teaching students how to program in python, you need a python programming environment simulator. But that tool won’t help a chemistry professor who really needs virtual labs and molecular modeling tools. And none of these tools are helpful for somebody teaching English composition. There simply isn’t a single generic learning environment that will work well for teaching all subjects. None of these tools will ever sell enough to make anybody rich.
Therefore, the companies that make these necessary niche teaching tools will tend to be small. In the early days of the LMS, they couldn’t afford to write a separate integration for every LMS. Which meant that not many specialized learning tools were created. As small as these companies’ target markets already were, many of them couldn’t afford to limit themselves to the subset of, say, chemistry professors whose universities happened to use Blackboard. It didn’t make economic sense.
LTI changed all that. Any learning tool provider could write integration once and have their product work with every LMS. Today, 1EdTech lists 240 products that are officially certified as supporting LTI interoperability standard. Many more support the standard but are not certified.
Would LTI have been created in a world in which generative AI existed? Maybe not. The most straightforward analogy is Zapier, which connects different software systems via their APIs. ChatGPT and its ilk could act as instant Zapier. A programmer using generative AI could use the API documentation of both systems, ask the generative AI to write integration to perform a particular purpose, and then ask the same AI for help with any debugging.
Again, notice that one still needs a programmer. Somebody needs to be able to read the APIs, understand the goals, think about the trade-offs, give the AI clear instructions, and check the finished program. The engineering skills are still necessary. But the work of actually writing the code is greatly reduced. Maybe by enough that generative AI would have made LTI unnecessary.
But probably not. LTI connections pass sensitive student identity and grade information back and forth. It has to be secure and reliable. The IT department has legal obligations, not to mention user expectations, that a well-tested standard helps alleviate (though not eliminate). On top of that, it’s just a bad idea to have spread bits of glue code here, there, and everywhere, regardless of whether a human or a machine writes it. Somebody—an architect—needs to look at the big picture. They need to think about maintainability, performance, security, data management, and a host of other concerns. There is value in having a single integration standard that has been widely vetted and follows a pattern of practices that IT managers can handle the same way across a wide range of product integrations.
At some point, if a software integration fails to pass student grades to the registrar or leaks personal data, a human is responsible. We’re not close to the point where we can turn over ethical or even intellectual responsibility for those challenges to a machine. If we’re not careful, generative AI will simply write spaghetti code much faster the old days.
The social element of knowledge work
More broadly, there are two major value components to the technical interoperability standards process. The first is obvious: technical interoperability. It’s the software. The second is where the deeper value lies. It’s in the conversation that leads to the software. I’ve participated in a 1EdTech specification working group. When the process went well, we learned from each other. Each person at that table brought a different set of experiences to an unsolved problem. In my case, the specification we were working on sent grade rosters from the SIS to the LMS and final grades back from the LMS to the SIS. It sounds simple. It isn’t. We each brought different experiences and lessons learned regarding many aspects of the problem, from how names are represented in different cultures to how SIS and LMS users think differently in ways that impact interoperability. In the short term, a standard is always a compromise. Each creator of a software system has to make adjustments that accommodate the many ways in which others thought differently when they built their own systems. But if the process works right, everybody goes home thinking a little differently about how their systems could be built better for everybody’s benefit. In the longer term, the systems we continue to build over time reflect the lessons we learn from each other.
Generative AI could make software integration easier. But without the conversation of the standards-making process, we would lose the opportunity to learn from each other. And if AI can reduce the time and cost of the former, then maybe participants in the standards-making effort will spend more time and energy on the latter. The process would have to be rejiggered somewhat. But at least in some cases, participants wouldn’t have to wait until the standard was finalized before they started working on implementing it. When the cost of implementation is low enough and the speed is fast enough, the process can become more of an iterative hackathon. Participants can build working prototypes more quickly. They would still have to go back to their respective organizations and do the hard work of thinking through the implications, finding problems or trade-offs and, eventually, hardening the code. But at least in some cases, parts of the standards-making process could be more fluid and rapidly iterative than they have been. We could learn from each other faster.
This same principle could apply inside any organization or partnership in which different groups are building different software components that need to work together. Actual knowledge of the code will still be important to check and improve the work of the AI in some cases and write code in others. Generative AI is not ready to replace high-quality engineers yet. But even as it improves, humans will still be needed.
Anthopologist John Seely Brown famously traced the drop in Xerox copier repair quality to a change in its lunch schedule for their repair technicians. It turns out that technicians learn a lot from solving real problems in the field and then sharing war stories with each other. When the company changed the schedule so that technicians had less time together, repair effectiveness dropped noticeably. I don’t know if a software program was used to optimize the scheduling but one could easily imagine that being the case. Algorithms are good at concrete problems like optimizing complex schedules. On the other hand, they have no visibility into what happens at lunch or around the coffee pot. Nobody writes those stories down. They can’t be ingested and processed by a large language model. Nor can they be put together in novel ways by quirky human minds to come up with new insights.
That’s true in the craft of copier repair and definitely true in the craft of software engineering. I can tell you from direct experience that interoperability standards-making is much the same. We couldn’t solve the seemingly simple problem of getting the SIS to talk to the LMS until we realized that registrars and academics think differently about what a “class” or a “course” is. We figured that out by talking with each other and with our customers.
At its heart, standards-making is a social process. It’s a group of people who have been working separately on solving similar problems coming together to develop a common solution. They do this because they’ve decided that the cost/benefit ratio of working together is better than the ratio they’ve achieved when working separately. AI lowers the costs of some work. But it doesn’t yet provide an alternative to that social interaction. If anything, it potentially lowers some of the costs of collaboration by making experimentation and iteration cheaper—if and only if the standards-making participants embrace and deliberately experiment with that change.
That’s especially true the more 1EdTech tries to have a direct role in what it refers to as “learning impact.”
The knowledge that’s not reflected in our words
In 2019, I was invited to give a talk at a 1EdTech summit, which I published a version of under the title “Pedagogical Intent and Designing for Inquiry.” Generative AI was nowhere on the scene at the time. But machine learning was. At the same time, long-running disappointment and disillusionment with learning analytics—analytics that actually measure students’ progress as they are learning—was palpable.
I opened my talk by speculating about how machine learning could have helped with SIS/LMS integration, much as I speculated earlier in the post about how generative AI might help with QTI:
Now, today, we would have a different possible way of solving that particular interoperability problem than the one we came up with over a decade ago. We could take a large data set of roster information exported from the SIS, both before and after the IT professionals massaged it for import into the LMS, and aim a machine learning algorithm at it. We then could use that algorithm as a translator. Could we solve such an interoperability problem this way? I think that we probably could. I would have been a weaker product manager had we done it that way, because I wouldn’t have gone through the learning experience that resulted from the conversations we had to develop the specification. As a general principle, I think we need to be wary of machine learning applications in which the machines are the only ones doing the learning. That said, we could have probably solved such a problem this way and might have been able to do it in a lot less time than it took for the humans to work it out.
I will argue that today’s EdTech interoperability challenges are different. That if we want to design interoperability for the purposes of insight into the teaching and learning process, then we cannot simply use clever algorithms to magically draw insights from the data, like a dehumidifier extracting water from thin air. Because the water isn’t there to be extracted. The insights we seek will not be anywhere in the data unless we make a conscious effort to put them there through design of our applications. In order to get real teaching and learning insights, we need to understand the intent of the students. And in order to understand that, we need insight into the learning design. We need to understand pedagogical intent.
That new need, in turn, will require new approaches in interoperability standards-making. As hard as the challenges of the last decade have been, the challenges of the next one are much harder. They will require different people at the table having different conversations.
The core problem is that the key element for interpreting both student progress and the effectiveness of digital learning experiences—pedagogical intent—is not encoded in most systems. No matter how big your data set is, it doesn’t help you if the data you need aren’t in it. For this reason, I argued, fancy machine learning tricks aren’t going to give us shortcuts.
That problem is the same, and perhaps even worse in some ways, with generative AI. All ChatGPT knows is what it’s read on the internet. And while it’s made progress in specific areas at reading between the lines, the fact is that important knowledge, including knowledge about applied learning design, simply is extremely scarce in the data it can access and even in the data living in our learning systems that it can’t access.
The point of my talk was that interoperability standards could help by supplying critical metadata—context—if only the standards makers set that as their purpose, rather than simply making sure that quiz questions end up in the right place when migrating from one LMS to another.
I chose to open the talk by highlighting the ambiguity of language that enables us to make art. I chose this passage from Shakespeare’s final masterpiece, The Tempest:
O wonder! How many goodly creatures are there here! How beauteous mankind is! O brave new world That has such people in’t!
William Shakespeare, The Tempest
It’s only four lines. And yet it is packed with double entendres and the ambiguity that gives actors room to make art:
Here’s the scene: Miranda, the speaker, is a young woman who has lived her entire life on an island with nobody but her father and a strange creature who she may think of as a brother, a friend, or a pet. One day, a ship becomes grounded on the shore of the island. And out of it comes, literally, a handsome prince, followed by a collection of strange (and presumably virile) sailors. It is this sight that prompts Miranda’s exclamation.
As with much of Shakespeare, there are multiple possible interpretations of her words, at least one of which is off-color. Miranda could be commenting on the hunka hunka manhood walking toward her.
“How beauteous mankind is!”
Or. She could be commenting on how her entire world has just shifted on its axis. Until that moment, she knew of only two other people in all of existence, each of who she had known her entire life and with each of whom she had a relationship that she understood so well that she took it for granted. Suddenly, there was literally a whole world of possible people and possible relationships that she had never considered before that moment.
“O brave new world / That has such people in’t”
So what is on Miranda’s mind when she speaks these lines? Is it lust? Wonder? Some combination of the two? Something else?
The text alone cannot tell us. The meaning is underdetermined by the data. Only with the metadata supplied by the actor (or the reader) can we arrive at a useful interpretation. That generative ambiguity is one of the aspects of Shakespeare’s work that makes it art.
But Miranda is a fictional character. There is no fact of the matter about what she is thinking. When we are trying to understand the mental state of a real-life human learner, then making up our own answer because the data are not dispositive is not OK. As educators, we have a moral responsibility to understand a real-life Miranda having a real-life learning experience so that we can support her on her journey.
Generative AI like ChatGPT can answer questions about different ways to interpret Miranda’s lines in the play because humans have written about this question and made their answers available on the internet. If you give the chatbot an unpublished piece of poetry and ask it for an interpretation, its answers are not likely to be reliably sophisticated. While larger models are getting better at reading between the lines—a topic for a future blog post—they are not remotely as good as humans are at this yet.
Making the implicit explicit
This limitation of language interpretation is central to the challenge of applying generative AI to learning design. ChatGPT has reignited fantasies about robot tutors in the sky. Unfortunately, we’re not giving the AI the critical information it needs to design effective learning experiences:
The challenge that we face as educators is that learning, which happens completely inside the heads of the learners, is invisible. We can not observe it directly. Accordingly, there are no direct constructs that represent it in the data. This isn’t a data science problem. It’s an education problem. The learning that is or isn’t happening in the students’ heads is invisible even in a face-to-face classroom. And the indirect traces we see of it are often highly ambiguous. Did the student correctly solve the physics problem because she understands the forces involved? Because she memorized a formula and recognized a situation in which it should be applied? Because she guessed right? The instructor can’t know the answer to this question unless she has designed a series of assessments that can disambiguate the student’s internal mental state.
In turn, if we want to find traces of the student’s learning (or lack thereof) in the data, we must understand the instructor’s pedagogical intent that motivates her learning design. What competency is the assessment question that the student answered incorrectly intended to assess? Is the question intended to be a formative assessment? Or summative? If it’s formative, is it a pre-test, where the instructor is trying to discover what the student knows before the lesson begins? Is it a check for understanding? A learn-by-doing exercise? Or maybe something that’s a little more complex to define because it’s embedded in a simulation? The answers to these questions can radically change the meaning we assign to a student’s incorrect answer to the assessment question. We can’t fully and confidently interpret what her answer means in terms of her learning progress without understanding the pedagogical intent of the assessment design.
But it’s very easy to pretend that we understand what the students’ answers mean. I could have chosen any one of many Shakespeare quotes to open this section, but the one I picked happens to be the very one from which Aldous Huxley derived the title of his dystopian novel Brave New World. In that story, intent was flattened through drugs, peer pressure, and conditioning. It was reduced to a small set of possible reactions that were useful in running the machine of society. Miranda’s words appear in the book in a bitterly ironic fashion from the mouth of the character John, a “savage” who has grown up outside of societal conditioning.
We can easily develop “analytics” that tell us whether students consistently answer assessment questions correctly. And we can pretend that “correct answer analytics” are equivalent to “learning analytics.” But they are not. If our educational technology is going to enable rich and authentic vision of learning rather than a dystopian reductivist parody of it, then our learning analytics must capture the nuances of pedagogical intent rather than flattening it.
A professor knows that her students tend to develop a common misconception that causes them to make practical mistakes when applying their knowledge. She very carefully crafts her course to address this misconception. She writes the content to address it. In her tests, she provides wrong answer choices—a.k.a. “distractors”—that students would choose if they had the misconception. She can tell, both individually and collectively, whether her students are getting stuck on the misconception by how often they pick the particular distractor that fits with their mistaken understanding. Then she writes feedback that the students see when they choose that particular wrong answer. She crafts it so that it doesn’t give away the correct answer but does encourage students to rethink their mistakes.
Imagine if all this information were encoded in the software. Their hierarchy would look something like this:
Here is learning objective (or competency) 1
Here is content about learning objective 1
Here is assessment question A about learning objective 1.
Here is distractor c in assessment question A. Distractor c addresses misconception alpha.
Here is feedback to distractor c. It is written specifically to help students rethink misconception alpha without giving away the answer to question A. This is critical because if we simply tell the student the answer to question A then we can’t get good data about the likelihood that the student has mastered learning objective 1.
All of that information is in the learning designer’s head and, somehow, implicitly embedded in the content in subtle details of the writing. But good luck teasing it out by just reading the textbook if you aren’t an experienced teacher of the subject yourself.
What if these relationships were explicit in the digital text? For individual students, we could tell which ones were getting stuck on a specific misconception. For whole courses, we could identify the spots that are causing significant numbers of students to get stuck on a learning objective or competency. And if that particular sticking point causes students to be more likely to fail either that course or a later course that relies on a correct understanding of a concept, then we could help more students persist, pass, stay in school, and graduate.
That’s how learning analytics can work if learning designers (or learning engineers) have tools that explicitly encode pedagogical intent into a machine-readable format. They can use machine learning to help them identify and smooth over tough spots where students tend to get stuck and fall behind. They can find the clues that help them identify hidden sticking points and adjust the learning experience to help students navigate those rough spots. We know this can work because, as I wrote about in 2012, Carnegie Mellon University (among others) has been refining this science and craft for decades.
Generative AI adds an interesting twist. The challenge with all this encoding of pedagogical intent is that it’s labor-intensive. Learning designers often don’t have time to focus on the work required to identify and improve small but high-value changes because they’re too busy getting the basics done. But generative AI that creates learning experiences modeled after thepedagogical metadata in the educational content it is trained on could provide a leg up. It could substantially speed up the work of writing the first-draft content so that designers can focus on the high-value improvements that humans are still better at than machines.
Realistically, for example, generative AI is not likely to know particular common misconceptions that block students from mastering a competency. Or how to probe for and remediate those misconceptions. But if were trained on the right models, it could generate good first-draft content through a standards-based metadata format that could be imported into a learning platform. The format would have explicit placeholders for those critical probes and hints. Human experts. supported by machine learning. could focus their time on finding and remediating these sticking points in the learning process. Their improvements would be encoded with metadata, providing the AI with better examples of what effective educational content looks like. Which would enable the AI to generate better first-draft content.
1EdTech could help bring about such a world through standards-making. But they’d have to think about the purpose of interoperability differently, bring different people to the table, and run a different kind of process.
O brave new world that has such skilled people in’t
I spoke recently to the head of product development for an AI-related infrastructure company. His product could enable me to eliminate hallucinations while maintaining references and links to original source materials, both of which would be important in generating educational content. I explained a more elaborate version of the basic idea in the previous section of this post.
“That’s a great idea,” he said. “I can think of a huge number of applications. My last job was at Google. The training was terrible.”
Google. The company that’s promoting the heck out of their free AI classes. The one that’s going to “disrupt the college degree” with their certificate programs. The one that everybody holds up as leading the way past traditional education and toward skills-based education.
Their training is “terrible.”
Yes. Of course it is. Because everybody’s training is terrible. Their learning designers have the same problem I described academic learning designers as having in the previous section. Too much to develop, too little time. Only much, much worse. Because they have far fewer course design experts (if you count faculty as course design experts). Those people are the first to get cut. And EdTech in the corporate space is generally even worse than academic EdTech. Worst of all? Nobody knows what anybody knows or what anybody needs to know.
Academia, including 1EdTech and several other standards bodies, funded by corporate foundations, are pouring incredible amounts of time, energy, and money into building a data pipeline for tracking skills. Skill taxonomies move from repositories to learning environments, where evidence of student mastery is attached to those skills in the form of badges or comprehensive learner records. Which are then sent off to repositories and wallets.
The problem is, pipelines are supposed to connect to endpoints. They move something valuable from the place where it is found to the place where it is needed. Many valuable skills are not well documented if they are documented at all. They appear quickly and change all the time. The field of knowledge management has largely failed to capture this information in a timely and useful way after decades of trying. And “knowledge” management has tended to focus on facts, which are easier to track than skills.
In other words, the biggest challenge that folks interested in job skills face is not an ocean of well-understood skill information that needs to be organized but rather a problem of non-consumption. There isn’t enough real-world, real-time skill information flowing into the pipeline and few people who have real uses for it on the other side. Almost nobody in any company turns to their L&D departments to solve the kinds of skills problems that help people become more productive and advance in their careers. Certainly not at scale.
But the raw materials for solving this problem exist. A CEO for HP once famously noted knows a lot. It just doesn’t know what it knows.
Knowledge workers do record new and important work-related information, even if it’s in the form of notes and rough documents. Increasingly, we have meeting transcripts thanks to videoconferencing and AI speech-to-text capabilities. These artifacts could be used to train a large language model on skills as they are emerging and needed. If we could dramatically lower the cost and time required to create just-in-time, just-enough skills training then the pipeline of skills taxonomies and skill tracking would become a lot more useful. And we’d learn a lot about how it needs to be designed because we’d have many more real-world applications.
The first pipeline we need is from skill discovery to learning content production. It’s a huge one, we’ve known about it for many decades, and we’ve made very little progress on it. Groups like 1EdTech could help us to finally make progress. But they’d have to rethink the role of interoperability standards in terms of the purpose and value of data, particularly in an AI-fueled world. This, in turn, would not only help match worker skills with labor market needs more quickly and efficiently but also create a huge industry of AI-aided learning engineers.
Summing it up
So where does this leave us? I see a few lessons:
In general, lowering the cost of coding through generative AI doesn’t eliminate the need for technical interoperability standards groups like 1EdTech. But it could narrow the value proposition for their work as currently applied in the market.
Software engineers, learning designers, and other skilled humans have important skills and tacit knowledge that don’t show up in text. It can’t be hoovered up by a generative AI that swallows the internet. Therefore, these skilled individuals will still be needed for some time to come.
We often gain access to tacit knowledge and valuable skills when skilled individuals talk to each other. The value of collaborative work, including standards work, is still high in a world of generative AI.
We can capture some of that tacit knowledge and those skills in machine-readable format if we set that as a goal. While doing so is not likely to lead to machines replacing humans in the near future (at least in the areas I’ve described in this post), it could lead to software that helps humans get more work done and spend more of their time working on hard problems that quirky, social human brains are good at solving.
1EdTech and its constituents have more to gain than to lose by embracing generative AI thoughtfully. While I won’t draw any grand generalizations from this, I invite you to apply the thought process of this blog post to your own worlds and see what you discover.
I’ve been having trouble blogging lately. Part of it has been that I’ve spent the last two years heads-down, building a business. But now that I’m looking around, I don’t see much happening in EdTech. Anywhere. I can write about big trends that will affect education. Plenty is happening in that arena. But at least at first glance, the EdTech sector looks frozen. I’m not talking about frozen as in the normal much-activity-but-little-progress way. I mean that, other than integrating ChatGPT into everything in shallow and trivial ways, I don’t see anybody doing much of anything.
I’m probably seeing an oversimplified picture. First, I have bigger blind spots than usual at the moment. Second, there’s so much happening in the macro-environment that some EdTech companies are probably working on larger plans behind the scenes. With changes like major demographic student switches, huge swathes of the economy being reconfigured, and profoundly impactful technologies popping up seemingly out of nowhere, companies need time to plan and implement appropriately significant responses.
But I also sense a lot of paralysis. Some may be confused about various large shifts and be confused about how to make sense of whatever sparse data they can get their hands on. (I certainly am.) They may not know what to do yet. And since we’re in a financial environment in which very few companies have a lot of money to spend, some EdTech firms may simply be unable to execute any strategy other than treading water at the moment.
Then again, some companies—even some industries—may not have effective responses to the changes. They may disappear.
I fed Bob Dylan’s famous line “He not busy born is busy dying” into OpenAI’s DALL-E 2 image generator, having very little idea of what the software would do with that prompt. Surprisingly, its output perfectly sums up my current thinking about the EdTech situation:
“He not busy born is busy dying,” words by Bob Dylan as interpreted by DALL-E 2
Clarity. It would be nice to have, wouldn’t it? Sadly, even in this age of magical AI genies, you can’t always get what you want.
“You can’t always get what you want,” words by The Rolling Stones as interpreted by DALL-E 2
But if you try sometimes, you get what you need. All I have is a bunch of older observations as a baseline, a few facts, a few conjectures, and a lot of questions. Still, that’s a place to start.
Shall we try?
A little context
Look, everything is a mess right now. Everybody knows it. Still, it’s worth taking a beat to remind ourselves that the landscape is at least as confusing for vendors as it is for universities.
First, there’s enrollment. We know that the United States is approaching the bottom of a long demographic dip in traditional college-aged students. We know it isn’t hitting every geographic area at the same time or with the same intensity. We know that the post-COVID labor market changes, the messed up supply chain that is still reconfiguring itself thanks to geopolitical changes, the tight labor market, the unwinding of a decade of high-stimulus monetary policy, and the high cost of college have all conspired to make enrollment changes odd, unpredictable, and unsettling. We have a handful of data points and endless surveys of student and work attitudes. And then there’s the looming potential recession. Nobody knows what will happen next year or the year after. Nobody knows what’s fleeting, somewhat long-term, or permanent.
If you’re building or running an EdTech company, how do you prepare for this? The most obvious strategy is to slash expenses and wait until the environment becomes clearer. That has worked in the past because, frankly, the education markets haven’t changed much or quickly. Downturns have been cyclical. This time may be different. In fact, it probably will be. But it’s hard to know how it will be different or how quickly it will change.
As universities realize that traditional enrollments may be harder to reach, I’m hearing a lot more talk about competency-based education (CBE), micro-credentials, and aligning education with skills, and work. Talk from universities. And a small number of industries, some of which (like allied healthcare) have been doing stackable micro-credentials for decades before that term was invented. Will the continuous education approach be taken up more broadly by a wider range of industries? Again, we have lots of surveys. I’ve not looked closely at the latest data. But nothing I’ve come across has convinced me that we actually know. What do you do about this if you’re an EdTech company? Pivots to corporate learning and development haven’t produced many great successes (although they have enabled some start-ups that would have folded to scrape along). There’s…something here. But what? How much do you bet on CBE taking off? And where do you place your chips?
We also know that generative AI is a big deal. How do we know? Mainly because ChatGPT and its growing list of competitors continue to surprise us. Whenever something we’ve built surprises us with regularity, that means we don’t understand its implications yet. Anyone who says they know what’s going to happen next is either reading too much science fiction, a billionaire who is used to saying made-up stuff without consequence, or both. So far in my world, most of the new “AI-powered” applications I’ve seen are hasty and trivial integrations with ChatGPT. They are so easy to reproduce that they are more likely to be feature sets than products.
That will change. But it will take a while. The underlying AI stack is evolving rapidly and could take multiple paths. Meanwhile, most folks are very early in their process of thinking about what the tools are and aren’t good for. Some industries have been thinking about, working with, and investing in AI in a serious way for some time. Education isn’t one of them. We’ve been caught flat-footed.
And unfortunately, most EdTech companies don’t have money to invest now even if they knew what to invest in. That’s true of startups, publicly traded companies, and private equity-held companies.
The start-up picture is brutal. Take a look at this investment trend:
Believe it or not, the chart understates just how bad the situation is. Last year, nearly half of all EdTech funding went to one company—BYJU’S—which is now struggling to make its debt payments. Three-fourths of all EdTech VC financing in 2022 went to just five start-ups. Given that the total pot shrank by 50% to begin with, there was nothing at all for most start-ups. This year isn’t exactly looking great either.
Nor are publicly traded EdTech companies faring better. Take a look at 2U’s stock price trend over the past five years:
Coursera doesn’t look so great either:
It’s weird to say, but this is one time that 2U and Coursera might prefer to be Pearson:
Then again, if we zoom out to look at a 10-year time horizon rather than 5 years, Pearson’s picture looks different:
Coursera, 2U, BYJU’S, and all the other EdTech unicorns should be worried that maybe they are Pearson. That their previous valuations were created by conditions that have come and gone, never to be seen again. Interest rates have stayed pinned at historic lows for the last fifteen years, ever since the Fed injected liquidity into the market to save the banking sector. The resulting cheap money was like rocket fuel for these companies and for the investors who funded them. It’s been easy, relative to historical norms, for somebody with money to seem like a genius by making more money. Meanwhile, EdTech business models are being tested in these turbulent times. Who will endure? Who will adapt? Who will catch a new wind in their sails? I don’t know.
In the coming months and years, we’re going to find out who the real geniuses are. Interest rates are not going back to where they were. Loan covenants will be more expensive, valuations will be harder to earn, and VCs will have a harder time raising money for their funds. And all this hits at a moment of great uncertainty and change in the sector.
It’s not surprising that EdTech is quiet at the moment. We’re in a pregnant pause as companies face the new realities confronting them and decide what to do. The question is, which of them are busy being born, and which are busy dying?
I’ll read the tea leaves. But as I wrote earlier, I have more questions than answers.
Textbook publishers
Yes, in 2023, the providers of digital curricular materials and interactive learning experiences are still widely called “textbook publishers.” It’s not for lack of trying to rebrand. For a while, McGraw-Hill Education was calling itself a “learning science company” and Pearson was calling itself a “learning company”. Maybe they still are.
The cynical jokes are much too easy here. Both companies made real efforts to transform themselves. For example, I wrote a post in 2013 about how Pearson was trying its rebuild the entire company, from HR policies upward, into one that was singularly focused on products that provided measurable improvements in student learning, or “efficacy”:
Love ’em or hate ’em, it’s hard to dispute that Pearson has an outsized impact on education in America. This huge company—they have a stock market valuation of $18 billion—touches all levels from kindergarten through career education, providing textbooks, homework platforms, high-stakes testing, and even helping to design entire online degree programs. So when they announce a major change in their corporate strategy, it is consequential.
That is one reason why I think that most everybody who is motivated to read this blog on a regular basis will also find it worthwhile to read Pearson’s startling publication, “The Incomplete Guide to Delivering Learning Outcomes” and, more generally, peruse their new efficacy web site. One of our goals for e-Literate is to explain what the industry is doing, why, and what it might mean for education. Finding the answers to these questions is often an exercise in reading the tea leaves, as Phil ably demonstrated in his recent posts on the Udacity/SJSU pilot and the layoffs at Desire2Learn. But this time is different. In all my years of covering the ed tech industry, I have never seen a company be so explicit and detailed about their strategy as Pearson is being now with their efficacy publications. Yes, there is plenty of marketing speak here. But there is also quite a bit about what they are actually doing as a company internally—details about pilots and quality reviews and hiring processes and M&A criteria. These are the gears that make a company go. The changes that Pearson is making in these areas are the best clues we can possibly have as to what the company really means when they say that they want efficacy to be at the core of their business going forward. And they have published this information for all the world to see.
These now-public details suggest a hugely ambitious change effort within the company.[…] I can say with absolute conviction that what Pearson has announced is no half-hearted attempt or PR window dressing, and I can say with equal conviction that what they are attempting will be enormously difficult to pull off. They are not screwing around. Whatever happens going forward, Pearson is likely to be a business school case study for the ages.
Pearson put out an announcement that looked like fluff, ultimately producing results that looked like fluff that blew away in the wind, but nevertheless tried very hard to change itself. For years.
The problem, as I noted back then, is that textbook companies like Pearson are neither positioned with their customers nor internally equipped to think about improving student success in a way that would be helpful:
Of course, Pearson[‘s] decision to pursue this strategy as what has historically been a textbook company also raises some different questions. As you think about Pearson declaring that they are now focused on evaluating all their products based on efficacy, one reaction that you may be having is something along the lines of, “Wait. You mean to tell me that, for all of those educational products you’ve been selling for all these years, your product teams are only now thinking about efficacy for the first time?” Another reaction might be, “Wait. You mean to tell me that you think that you, a textbook company, should be defining the learning outcomes and determining the effectiveness of a course rather than the faculty who teach the course?”[…]
It’s impossible to unpack the meaning of Pearson’s move without putting it in the context of the historical relationship between the textbook industry and the teachers who adopt their products. Despite all of the complaints about how bad textbooks are and how clueless these companies are, the relationship between textbook publishers and faculty is unusually intimate. To begin with, I can’t think of any other kind of company that hires literally thousands of sales representatives whose job it is to go visit individual faculty, show them the company’s products, answer questions, and bring feedback on the products back to the company. And speaking of those products, the overwhelming majority of them are written by faculty—many with input from an advisory committee of faculty and pre-publication reviews by other faculty. You can fairly accuse the textbook publishers of many different faults and sins, but not taking faculty input seriously isn’t one of them. Historically, they have relied heavily on that faculty input to shape the pedagogical features on the textbooks. And they have had to, because most of the editors are not teachers themselves. More often than not, they started off as textbook sales reps. If they taught at all, it was typically ten or twenty years ago, and just for a few a few years—long enough for them to figure out that teaching and the academic life weren’t for them. This doesn’t mean that they don’t care about pedagogy or don’t know anything about it, but it does mean that most of what they know comes from talking with their authors and customers.
And by “customers,” I mean faculty, despite the fact that it is the students who actually buy the product. Pearson’s choice to build their learning outcomes effort around a term that comes from the pharmaceutical industry is an historically apt one for the textbook industry. In higher education in the United States, faculty prescribe textbooks and students purchase them. As a result, textbook publishers have generally designed their products to please faculty rather than students. One consequence of this is that they had no need to distinguish product features that offer faculty convenience from those that actually impact student learning. When faculty/customers said to the textbook publishers, “I want my book to come with slides, lecture notes, and a self-grading homework platform so that I don’t have to put as much work into that annoying survey course the department head is making me teach,” then that’s what they provided. Whether that collection of materials had positive impact, negative impact, or no impact on student outcomes was not a question that the textbook publisher had any particular reason to ask. For the most part, the publishers relied on their authors and customers to make good decisions for the students. As long as the they provided the raw materials that the faculty said they needed, the companies’ work was done.
Nothing in Pearson’s history prepared it to think about how effective its products are at helping students learn. That wasn’t what its customers had looked to it for. They had little data and little historic expertise from which to start their transformation. By and large, their digital products were not designed to provide data necessary to improve student learning, never mind.
Worse, they really didn’t know how to work with their customers on their new mission. Academic institutions were not about to cede their responsibility for student success to textbook publishers. It would have to be some kind of partnership. But Pearson and their peers had no idea what that partnership should look like.
Internally, changing the way they think about answering the questions that the framework asks them will entail as much subtle, difficult, and pervasive re-engineering of the corporate reflexes and business processes as the work being undertaken now. As I described earlier, all textbook companies that have been around for a while are wired for a particular relationship with faculty that is at the heart of how they design, produce, and sell their products. Their editors have gone through decades of tuning the way they think and work to this process, and so have their customers. When Pearson layers a discussion of efficacy onto these business processes, a tension is created between the old and new ways of doing things. Suddenly, authors and customers don’t necessarily get what they want from their products just because they asked for them. There are potentially conflicting criteria. The framework itself provides nothing to help resolve this tension. At best, it potentially scaffolds a norming conversation. But a product management methodology that can combine knowledge about efficacy, user desires, and usability requires more tools than that. And that problem is even worse in some ways now that product teams have multiple specialized roles. The editor, author, adopting teacher, instructional designer, cognitive science researcher, psychometrician, data scientist, and UX engineer may all work together to develop a unified vision for a product, but more often than not they are like the blind man and the elephant. Agreeing in principle on what attributes an effective product might have is not at all the same as being able to design a product to be effective, where “effective” is shared notion between the company and the customers.
Pearson will need to create a new methodology and weave it into the fabric of the company. There are a number of sources from which they can draw. The Incomplete Guide mentions Lean Startup techniques, which are as good a place to start as any. But there is no methodology I know of that will work off-the-rack for education, and there certainly is no talent pool that has been trained in any such methodology. I have worked with multiple educational technology product teams in multiple companies on just this problem, and it is very, very hard. In fact, it may be the single hardest problem that the educational technology industry faces today, as well as one of the harder problems that the larger educational community faces.
In retrospect, the fatal flaw in the industry may be its very raison d’être. In the analog world, textbook publishers enabled faculty to outsource portions of their course designs to other faculty who, as authors, were aided in design, production, sales, and distribution by the companies. Because the products were just pages in a book, their adopters could pick and choose what they used and how they used it. But they also had to pick and choose. And adapt. And fill in gaps. That process, the work of turning raw curricular materials into a finished, tailored curricular experience, is increasingly where the value is. It was in 2013 and it certainly is now. But nobody turns to textbook publishers to help with that job.
I wrestled with this same problem when I was an employee at Cengage, just a couple of years before I wrote the Pearson post. MindTap was the first learning platform from a major publisher to shift the paradigm from a learning experience modeled after a classroom—the LMS—to one that centered on the substance of the course itself. It started with a loose book metaphor—think “scope and sequence”—but was very flexible and configurable. Beyond our plan to support all the LTI tools that plug into an LMS, we had a very flexible MindApps API that enabled a richer integration. For example, we integrated several different note-taking apps. Students using, say, Evernote, could take their notes in the margin of a MindTap title. The content would be synchronized with Evernote. And it would stay in the students’ note-taking app forever. MindTap was intended to be the hub, but not the walled garden, of a new, more expansive digital learning ecosystem. One that was centered on tailored, student-centered learning design rather than on publisher content.
Customers liked MindTap a lot. Some of them liked Cengage’s textbook franchises less. They wanted to license the platform and put their own content in it. Despite the urging of some of us both inside and outside the company, Cengage refused. The company was focused on the value of its content.
Since I wrote my Pearson efficacy post, which was the same year that the firm’s stock price peaked in that 10-year graph above, publishers have lost 35% of their revenues. They have been bought by private equity firms, filed for bankruptcy, tried and failed to merge, bought OPM companies only to put them up for sale, and tried many other tactics. Nothing has worked.
Generative AI is a commoditizing force. It is a tsunami of creative destruction.
Consider the textbook industry. As long-time e-Literate readers know, I’ve been thinking a lot about how its story will end. Because of its unusual economic moats, it is one of the last media product categories to be decimated or disrupted by the internet. But those moats have been drained one by one. Its army of sales reps physically knocking on campus doors? Gone. The value of those expensive print production and distribution capabilities? Gone. Brand reputation? Long gone.
Just a few days ago, Cengage announced a $500 million cash infusion from its private equity owner[….]
What will happen to this tottering industry when professors, perhaps with the help of on-campus learning designers, can use an LLM to spit out their own textbooks tuned to the way they teach? What will happen when the big online universities decide they want to produce their own content that’s aligned with their competencies and is tied to assessments that they can track and tune themselves?
Don’t be fooled by the LLM hallucination fear. The technology doesn’t need to (and shouldn’t) produce a perfect, finished draft with zero human supervision. It just needs to lower the work required from expert humans enough that producing a finished, student-safe curricular product will be worth the effort.
How hard would it be for LLM-powered individual authors to replace the textbook industry? A recent contest challenged AI researchers to develop systems that match human judgment in scoring free text short-answer questions. “The winners were identified based on the accuracy of automated scores compared to human agreement and lack of bias observed in their predictions.” Six entrants met the challenge. All six were built on LLMs.
This is a harder test than generating anything in a typical textbook or courseware product today.
The textbook industry has received ongoing investment from private equity because of its slow rate of decay. Publishers threw off enough cash that the slum lords who owned them could milk their thirty-year-old platforms, twenty-year-old textbook franchises, and $75 PDFs for cash. As the Cengage announcement shows, that model is already starting to break down.
How long will it take before generative AI causes what’s left of this industry to visibly and rapidly disintegrate? I predict 24 months at most.
This week I saw a quick, offhand demonstration of a platform provider’s integration of generative AI into their system to create structured learning content. It worked. That conversation, along with investigations and experiments I’m running in preparation for an EEP project on the topic, strongly suggest to me that the tech is good enough today to change the economics of course design enough to completely disrupt the old publisher model.
I don’t think the next step is “robot tutor in the sky 2.0.” But fundamentally changing the economics of learning design is entirely plausible in the near term. AI will assist learning designers rather than replace them. It will make the job much easier, more affordable, and quite possibly more fulfilling for the people doing the work. It will be so cheap that it won’t even be a product. It’ll be a feature set.
I believe the era of AI-assisted OER and local design is coming. That could be exciting, right?
But it hasn’t happened yet.
At this moment, we’re waiting. Meanwhile, the publishers must see what’s coming. What are they doing to prepare? Generative AI is going to shift the value of digital learning products from the content to the platform and from crafted finished products to products that enable craft. Theoretically, it may not be too late for the publishers to respond. In practice, I’ve heard from friends in the industry that their employers have been disinvesting in their platforms over the past few years. I don’t know what they’re thinking right now.
So we’ll wait and see.
LMSs
We could call the textbook publishers’ root problem one of product/market fit. Their product no longer meets the needs of the market and they haven’t been well-equipped to either change their product or focus on a different market.
Many have argued for a long time that this is true with the LMS. That the product category is going to die. The people making that argument have been wrong. Repeatedly. Forever. For so long, in fact, that the loudest voices in this camp have largely left EdTech.
But are they finally right? I don’t know.
Before I get into the details, here’s a depressing question: How many broadly used EdTech product categories can you think of that were created since the invention of the LMS?
Yes, shift happens. But less often than one might hope.
Back in 2014, I wrote an unintentionally infamous rant called Dammit, the LMS in which I took on all the critics who were arguing the LMS was dead or dying. I’ll quote at length because it gets to the heart of the product/market fit conundrum:
Let’s imagine a world in which universities, not vendors, designed and built our online learning environments. Where students and teachers put their heads together to design the perfect system. What wonders would they come up with? What would they build?
Why, they would build an LMS. They did build an LMS. Blackboard started as a system designed by a professor and a TA at Cornell University. Desire2Learn (a.k.a. Brightspace) was designed by a student at the University of Waterloo. Moodle was the project of a graduate student at Curtin University in Australia. Sakai was built by a consortium of universities. WebCT was started at the University of British Columbia. ANGEL at Indiana University.
OK, those are all ancient history. Suppose that now, after the consumer web revolution, you were to get a couple of super-bright young graduate students who hate their school’s LMS to go on a road trip, talk to a whole bunch of teachers and students at different schools, and design a modern learning platform from the ground up using Agile and Lean methodologies. What would they build?
They would build Instructure Canvas. They did build Instructure Canvas. Presumably because that’s what the people they spoke to asked them to build.
In fairness, Canvas isn’t only a traditional LMS with a better user experience. It has a few twists. For example, from the very beginning, you could make your course 100% open in Canvas. If you want to teach out on the internet, undisguised and naked, making your Canvas course site just one class resource of many on the open web, you can. And we all know what happened because of that. Faculty everywhere began opening up their classes. It was sunlight and fresh air for everyone! No more walled gardens for us, no sirree Bob.
That is how it went, isn’t it?
Isn’t it?
I asked Brian Whitmer the percentage of courses on Canvas that faculty have made completely open. He didn’t have an exact number handy but said that it’s “really low.” Apparently, lots of faculty still like their gardens walled. Today, in 2014.
Canvas was a runaway hit from the start, but not because of its openness. Do you know what did it? Do you know what single set of capabilities, more than any other, catapulted it to the top of the charts, enabling it to surpass D2L in market share in just a few years? Do you know what the feature set was that had faculty from Albany to Anaheim falling to their knees, tears of joy streaming down their faces, and proclaiming with cracking, emotion-laden voices, “Finally, an LMS company that understands me!”?
It was Speed Grader. Ask anyone who has been involved in an LMS selection process, particularly during those first few years of Canvas sales.
Here’s the hard truth: While [one LMS critic] wants to think of the LMS as “training wheels” for the internet (like AOL was), there is overwhelming evidence that lots of faculty want those training wheels. They ask for them. And when given a chance to take the training wheels off, they usually don’t.[…]
Do you want to know why the LMS has barely evolved at all over the last twenty years and will probably barely evolve at all over the next twenty years? It’s not because the terrible, horrible, no-good LMS vendors are trying to suck the blood out of the poor universities. It’s not because the terrible, horrible, no-good university administrators are trying to build a panopticon in which they can oppress the faculty. The reason that we get more of the same year after year is that, year after year, when faculty are given an opportunity to ask for what they want, they ask for more of the same. It’s because every LMS review process I have ever seen goes something like this:
Professor John proclaims that he spent the last five years figuring out how to get his Blackboard course the way he likes it and, dammit, he is not moving to another LMS unless it works exactly the same as Blackboard.
Professor Jane says that she hates Blackboard, would never use it, runs her own Moodle installation for her classes off her computer at home, and will not move to another LMS unless it works exactly the same as Moodle.
Professor Pat doesn’t have strong opinions about any one LMS over the others except that there are three features in Canvas that must be in whatever platform they choose.
The selection committee declares that whatever LMS the university chooses next must work exactly like Blackboard and exactly like Moodle while having all the features of Canvas. Oh, and it must be “innovative” and “next-generation” too, because we’re sick of LMSs that all look and work the same.
Nobody comes to the table with an affirmative vision of what an online learning environment should look like or how it should work. Instead, they come with this year’s checklists, which are derived from last year’s checklists. Rather than coming with ideas of what they could have, the come with their fears of what they might lose. When LMS vendors or open source projects invent some innovative new feature, that feature gets added to next year’s checklist if it avoids disrupting the rest of the way the system works and mostly gets ignored or rejected to the degree that it enables (or, heaven forbid, requires) substantial change in current classroom practices.
This is why we can’t have nice things.[…]
There. I did it. I wrote the damned “future of the LMS” post. And I did it mostly by copying and pasting from posts I wrote 10 years ago. I am now going to go pour myself a drink. Somebody please wake me again in another decade.
Well, here we are. A decade later. Has anything changed? I’m told that something called a “Next Generation Digital Learning Environment (NGDLE)” popped up during my slumber. But it was gone by the time I woke up. Other than that, my friends in the trenches tell me that largely, no, not much has changed. The rapid shifts in market share of various LMSs have slowed now that Blackboard has staunched the bleeding. (Former Instructure CEO Josh Coates once told me, “We know we can’t keep feeding off Blackboard’s carcass forever.”) Moodle is still out there, Moodling along. Every once and a while, I get a question from somebody about whether they should choose D2L Brightspace or Instructure Canvas. Invariably, their question ends with some version of, “It probably doesn’t matter much, right? I mean, they’re pretty much the same.” My answer has been, “That’s mostly true, except when it’s not. The differences might or might not matter to you depending on the specifics of how you’re using the system.” Nothing in the ecosystem has forced shift. Customers complained but didn’t demand anything different. Quite the opposite.
That said, I’m sensing that more may be shifting than is apparent on the surface. How much will change and how much those changes will matter both remain to be seen.
Instructure and Blackboard are both owned by Private Equity companies now. While that sentence often cues ominous music, I’m not sure it’s the case here. Blackboard is part of Anthology, which does…well…honestly, I’m not entirely clear. (I guess it’s time for Rip Van Winkle to have a look around again.) At first glance, it looks to me like they have a student administration and success platform along with a bunch of services. So…that’s different. They also have the Ally accessibility management tool, which is one of the very few products I’ve seen customers get genuinely excited about in EdTech. When I add those pieces up, I…well…I can’t add them up yet. There’s too much I don’t understand. At some point, I’ll reach out to my friends at the company and get a clearer picture from them.
Instructure bought Badgr and seems to be leaning into CBE. They also bought…a digital adoption platform? I worked extensively with that tech in corporate L&D 20 years ago, long before SaaS and product-led growth. Back then, we mostly used it to boost worker productivity when using complex and confusing software applications. I always wondered why the product category didn’t catch on in education and training. Anyway, Instructure has made a couple of interesting and surprising tuck-in acquisitions. Is there a larger strategy here? Again, I should ask my friends over there.
D2L has been making some early moves into content production (building on an infrastructure that’s always been relatively better than its competitors for learning design) and has been quietly rebuilding its architecture into microservices in a Ship of Theseus sort of way. In their case, I actually have been talking to them a bit about what they’re up to. I’m not clear on the degree to which they’ve converged on a holistic strategy but they definitely have some interesting moves in mind. I’ll have to find out from them what I can share and probe a little more about how it all adds up.
In total, it feels like these companies are getting ready to finally differentiate from each other, not because existing customers are demanding change but because the market is saturated. Everybody in higher ed has an LMS. International growth is…fine, but not transformative. K12 and corporate markets are tougher than they appeared to be. LMS companies are not going to get enough growth by just selling the same product to more customers. They need to either sell different stuff to their existing customers or rethink their core product so that it’s useful in big new ways that attract different customers. They have to find new needs to satisfy. Each of the major higher education LMS companies appears to be approaching the challenge in a different way.
That would (finally) be interesting, wouldn’t it? But again, not much visible has happened yet. The Blackboard thing seems pretty dramatic. But I haven’t yet heard from anyone who thinks it will change the market meaningfully. Blackboard doesn’t even come up in any LMS selection conversations that I’ve had.
One area we might see an opportunity to change the value proposition could come from…wait for it…generative AI. If learning design and content generation costs are dropping through the floor, then the value shifts to platforms that can generate those experiences, fine-tune them, run them for students, and return data back. Is the LMS the right platform for that? It hasn’t been a great fit so far, but…maybe?
OPMs
I don’t know what to say about OPMs because I don’t know what they are anymore. If Coursera, Noodle Partners, iDesign, Guild Education, and Project Kittyhawk can all be considered OPMs, then it’s hard to have a coherent conversation about the “product category.”
Very roughly, the market seems to have bifurcated. The biggest players are sticking to their roots, which is helping universities find more enrollments. Yes, yes, they provide many other services, stand for mom and apple pie, yada yada yada. But at their heart, they help universities expand their ability to spin up, market, and sell more online programs. This is rapidly evolving into a technology platform game, which may be one reason why the Department of Education’s “dear colleague” letter took such a broad swipe at EdTech and not just traditional OPM services. As I wrote in “Coursera is Evolving into a Third-Wave EdTech Company,”
Coursera has always thought of itself as a two-sided market. For those unfamiliar with the term, a two-sided market is one where the company’s primary business is to connect buyers with sellers. Amazon, Etsy, Airbnb, and Uber are all examples of this sort of business. Yes, they were attached in the early days to selling a particular form of MOOC as an individual product, much as Amazon only sold books in the early days. Much of the attention during the early years of MOOCs was on the pedagogical model of the MOOC itself, which is not very effective, and on the MOOC course delivery platforms, which directly translated lecture-model courses into an infinite lecture hall, with some relatively modest technological improvements. The innovation that got the least attention at the time was Coursera’s nature as a two-sided market. I remember talking to Daphne Koller about this circa 2014 (in front of one of those ridiculous fountains in the Swan and Dolphin Hotel at a Sloan-C conference).
I’m not sure that EdX ever fully grasped the implications of the two-sided market model. 2U might; it’s hard to tell right now. The company’s in-process rebranding is confusing and their clearest marketing point so far has been that MOOCs lower the advertising costs for degree programs. Coursera, on the other hand, understood the business model implications early on, one of which is that two-sided markets tend to produce one big winner in any given space. Who is the second-largest competitor to Amazon? Walmart? Wayfair? The distributed network of stores that Shopify powers? I don’t know. The answer isn’t obvious. It’s not like Coke and Pepsi….
The Coursera platform, writ large, connects universities, learners, government agencies, megacorporations, and local employers. It helps open up new opportunities for universities to reach students without falling afoul of the “dialing for dollars” problem that plagued for-profit universities and create ethical and legal complexities for OPMs.
A multi-sided market also offers some benefits to the educational mission relative to other models. If, for example, you’re an OPM that has heavily subsidized the creation of a degree program in exchange for a share of the revenues for ten years, then you need to make sure your up-front investment pays off. This is true of any business that invests up-front in building products, including textbook publishers. In a multi-sided market, depending on how the compensation is set up, the marketplace owner shouldn’t care much about whether the company sells 100,000 units of one product or 1,000 units each of 100 products. For education, some programs are essential for students, local economies, and important business niches, even if they don’t require a lot of trained individuals. So a well-functioning multi-sided market should, all else being equal, offer more educational opportunities within a scalable model.
Amazon, at its heart, is a way for product vendors to sell more stuff to more people with less effort. MOOC platforms, as they exist today, seem to be a way for certificate and degree vendors to sell more stuff to more people with less effort. Sure, the MOOC companies have course authoring and delivery platforms underneath. But nobody would care about those platforms if they weren’t attached to a marketplace. I know a handful of American universities that adopted OpenEdX as a stand-alone learning platform. Most have dropped it. I haven’t heard anybody begging for Coursera to make its platform available separate from the marketplace either.
This is why Guild is now getting lumped as an OPM with increasing frequency. If you think the point of an OPM is to fill more seats in online programs, well, that’s what Guild does. So yeah, it’s hard to define what an OPM is or how it works, which may be why the Department of Education seems confused on the topic.
Is this part of the space evolving? I don’t know. Everybody is so cash-constrained right now. I haven’t noticed the big players making any big moves. Also, their strategies feel incomplete to me. I see a lot more movement inside some universities toward competencies. The platforms do help break down the degree into smaller marketable units and sell enough of them to give them credibility. A “MicroMasters” is a thing now. Sort of. But overall, the connective tissue with employers, both on skills definition and on proof of competency driving employment, is still pretty sketchy except in a few niches.
Meanwhile, fee-for-service shops like iDesign seem focused on helping universities build capacity of various forms—mostly in program and course design. That’s great. It’s needed. But it will never be a giant business. And I’m not sure if generative AI helps or hurts them. They may find themselves having to react to moves made by better-funded learning platform companies. Or not. There’s nothing about generative AI that would require the resources of a big LMS or courseware delivery platform company to deliver value.
The OPM gold rush has run its course. Now we have chaos. Something, or some things, are going to emerge out of it. But I don’t know what they will be or what value they will provide. Or when. Or from which providers.
What else is there?
As usual, I won’t write about ERP and CRM. Not because they’re unimportant. They’re very important. But they’re also an entirely different sort of mess. For reasons that I won’t go into, these product categories are incredibly difficult to make work smoothly and intuitively in education, where complex workflows vary so widely. Until I see signs that this fundamental dynamic is shifting, I won’t devote significant attention to following these big enterprise systems.
I could run down a list of product categories that either completely imploded or are struggling along. Learning analytics. Courseware platforms. ePortfolios (a.k.a. Comprehensive Learner Records?). Some of these may become more interesting than they have been. I’ll save them for future posts.
What else?
AI, AI, AI. Nobody has any money to invest or spend on anything except on AI. So far, most of the product ideas I’ve seen are either trivial or pie-in-the-sky. My AI noise filter is set pretty high at the moment. But I’m going to start lowering it a bit. There are some folks who have been thinking and working hard on real products since before the ChatGPT hype hit (some of whom have been very persistently and creatively trying to get my attention). I will start taking a few of these calls. A few. At this point, I’m looking for thoughtful approaches, realistic thinking about the tech, and identification of real and solvable problems. I don’t expect the products to be right yet. I’m more interested in the people.
On the bigger picture, I read countless articles about AI and the future of work. While that kind of thinking is fine and probably necessary to a point, I personally don’t like to write about possible changes that are further out than I can see clearly. I can see AI having a direct impact in several areas, which I will write about as opportunities come into focus. There will be impacts on education and EdTech in the near future, some of which I may see coming and some of which I definitely won’t. None of it is quite here yet. Generally speaking, we tend to overestimate how quickly these technologies will penetrate particular markets because we forget about all the human stuff that gets in the way. And there is a lot of human stuff in education.
That said, one of the more remarkable affordances of generative AI is its ability to make natural language function as both a user interface and a programming language. It reduces friction like nothing I’ve ever seen before. So maybe we’ll see meaningful innovation faster this time.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
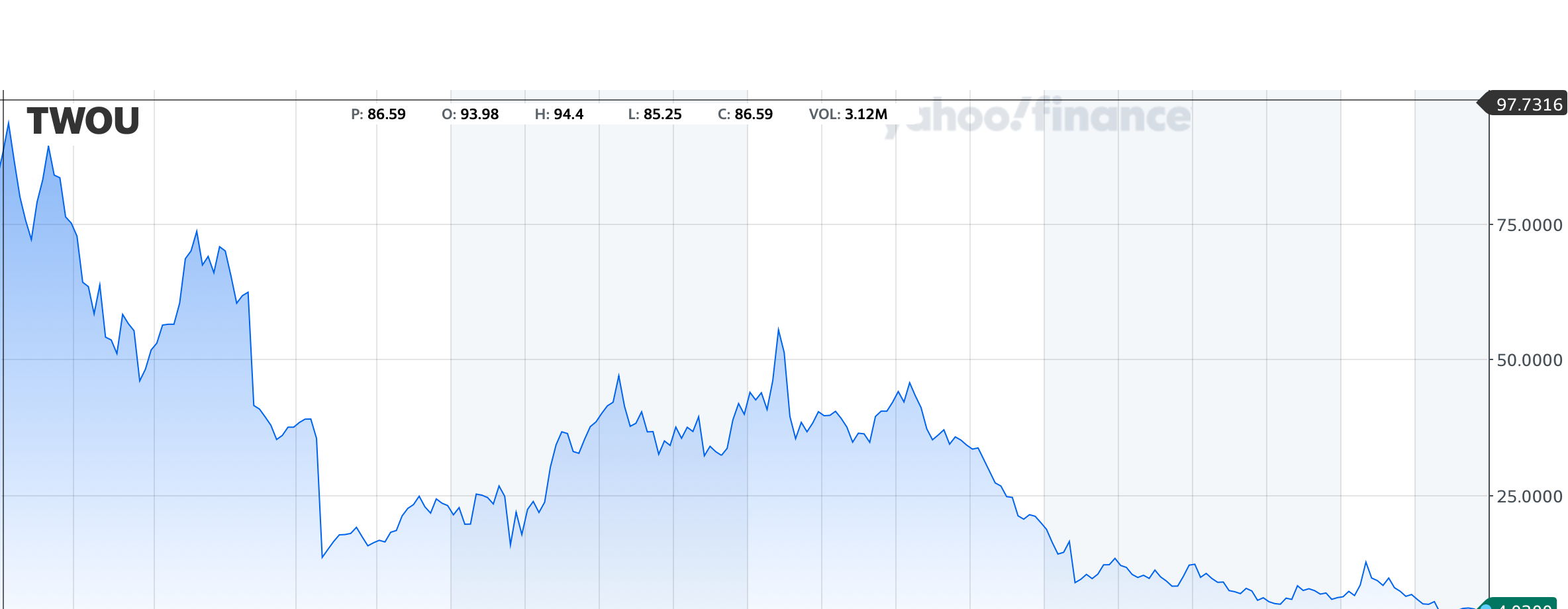{kind=link}
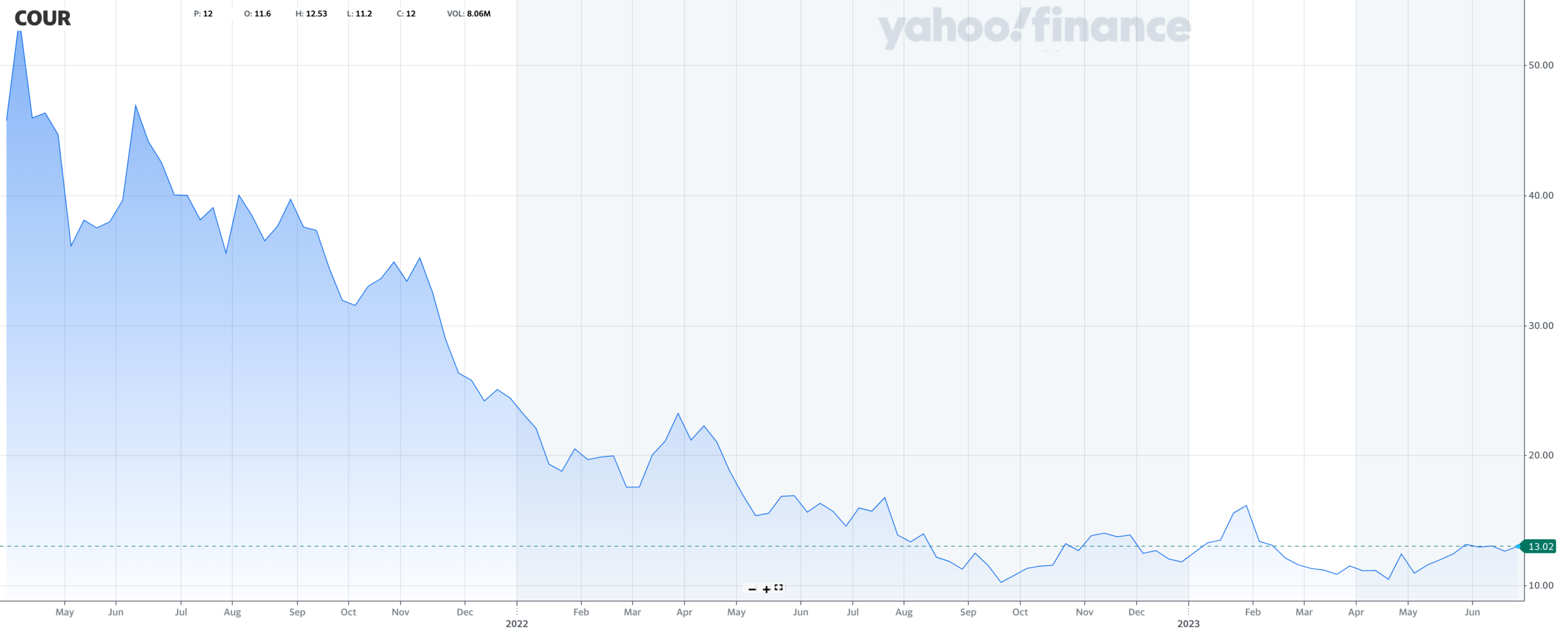{kind=link}
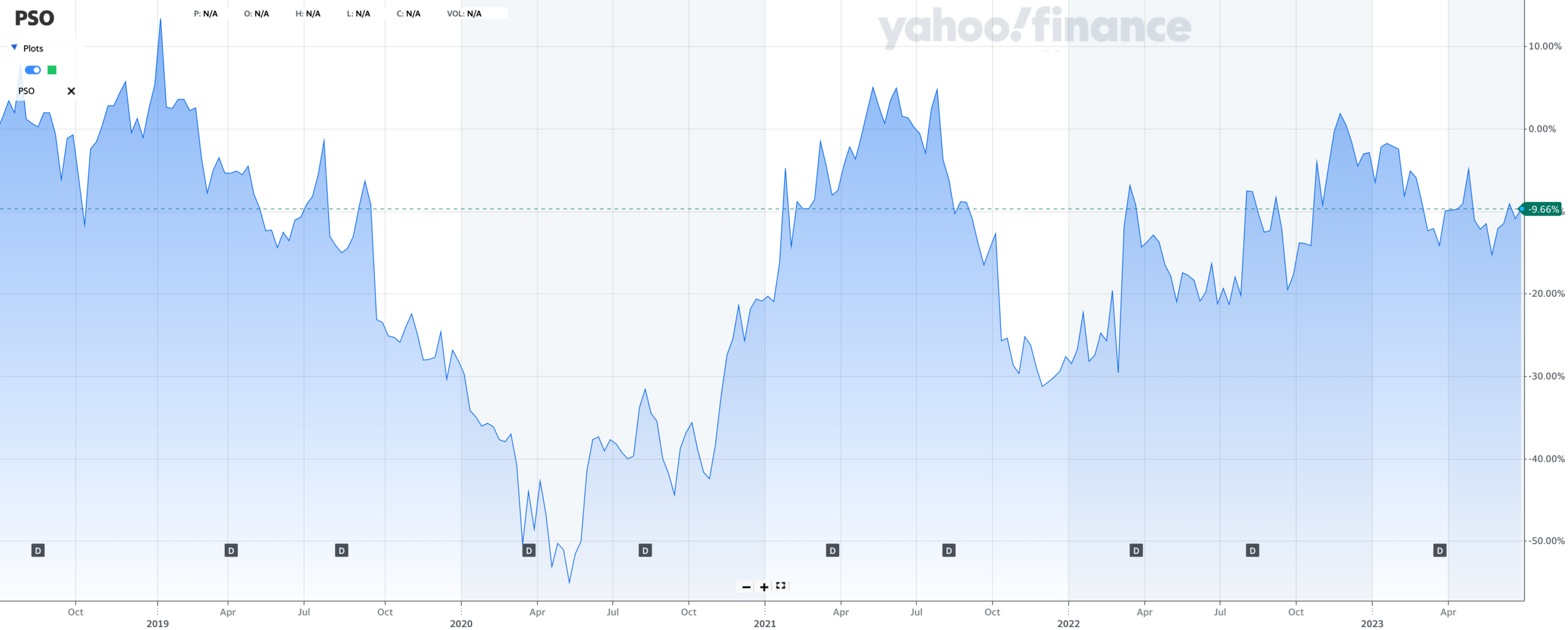{kind=link}
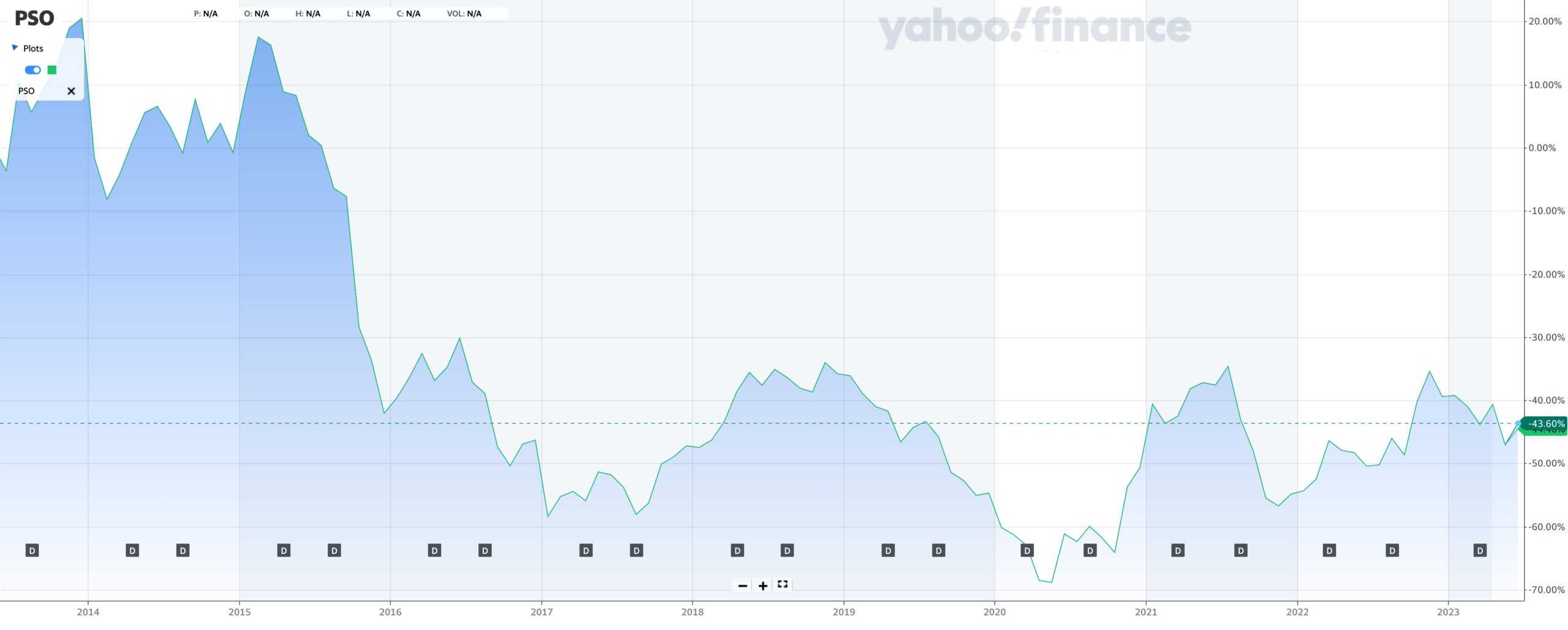{kind=link}