By mirroring gender pay gap reporting, which was made mandatory in 2018, the Equality (Race and Disability) Bill would introduce mandatory ethnicity and disability pay gap reporting for large employers with 250 or more employers.
Diving into the data, we were concerned to find that no progress has been made in reducing the median gross hourly pay gap for Black, African, Caribbean or Black British employees compared to white employees, remaining “consistent since 2012”. The disability pay gap is even more pronounced, at 12.7 per cent, having remained “relatively stable since 2014.” The lack of progress in closing these pay gaps is as concerning as the lack of awareness of the problem.
Conversely, the practice of gender pay gap reporting will have contributed to the gender pay gap declining by approximately a quarter among full-time employees over the past decade. Greater transparency helped build the foundations for positive transformation, creating a strategic imperative to root out systemic inequalities and leading to many employers developing, and proactively publishing, action plans to close the gap within their organisations.
In pursuing the noble aim of creating a more equal – and socially cohesive – society, the same focus must now be placed on tackling racial and disability inequalities. Economic inequalities between ethnic groups are an important contributor to social unrest.
The government should be supported in its proposed introduction of the Equality (Race and Disability) Bill and, speaking as vice chancellor of Birmingham City University (BCU), David would encourage fellow higher education leaders to join him in lending our public support to the government for this proposal.
There are two key reasons for higher education institutions publicising their ethnicity pay gaps in particular: to build trust with their internal community, and to strengthen authentically social cohesiveness in their local communities.
Building trust
BCU’s new strategy articulates a clear commitment to improve the diversity of our organisation at all levels and eradicate pay gaps. The first step in this will be to publish all our pay gaps with a clear plan to close them by 2030.
There are persistent racial inequalities in higher education. This is demonstrated most evidently in awarding gaps for ethnic minority students and Black students achieving a good honours degrees compared to white students, at 14.1 per cent and 21.6 per cent respectively in 2024. A lack of representation of ethnic minority staff in senior positions also conveys persistent inequities. Ethnic minorities now comprise one in three undergraduate students, but only one in four (20.2 per cent) of academic staff. Their representation is even lower among professors (15.1 per cent), senior managers (9.1 per cent) and executives (7 per cent).
The picture is more concerning in terms of Black representation in higher education. One in ten undergraduate students is Black (9.6 per cent), but only one in every roughly 27 academics share their ethnic identity. Only 1.6 per cent of all professors are black and 0.7 per cent of executives.
In contrast to the gender pay gap, information on the ethnicity pay gap in higher education is not routinely published. Combined with the lack of proportional representation of ethnic minority staff in senior positions, the lack of published data and strategy to tackle pay gaps has caused many staff to lose trust in institutional leadership and its commitment to tackle racial inequalities. The Equality (Race and Disability) Bill would bring parity with mandatory gender pay gap reporting and offer greater transparency to our communities.
Working effectively with our diverse local communities necessitates trust and the transparent reporting of systemic racial inequalities is paramount. For BCU, this means better reflecting and working in partnership with a community in which no ethnic group has a majority; the 2021 census identified that Birmingham’s population is more than twice as likely to come from an ethnic minority than the overall population in England. 51.4 per cent of people living in Birmingham are from an ethnic minority group, compared to a national average in England of 19 per cent. The data is much more profound for Ladywood, the constituency in which BCU’s city centre campus is based. Here, more than three in four (76.6 per cent) come from an ethnic minority, with the greater proportions of Asian (38.6 per cent) and Black (25.9 per cent) than White (23.4 per cent) citizens.
Birmingham’s “super-diversity” is seen as one of its biggest strengths, the city council opining that it stems from the city’s long-standing history for welcoming people from around the world. However, we must recognise that challenges persist, most notably in terms of engendering social harmony and tackling inequality. Those two challenges are interlinked: social harmony rests on our different racial and ethnic groups feeling valued and having trust in their local institutions providing equal opportunities and equitable outcomes, regardless of background.
Our 2030 strategy sets out a clear vision to be an exemplar anchor institution by 2030. This vision was co-created with representatives from our communities, who recognise and value the crucial role that universities like ours play in their locality. Our strategy explicitly recognises the responsibility we have in strengthening social cohesion in our home city of Birmingham.
From speaking with many vice chancellors, I know that we at BCU are not alone in championing our civic mission. Notwithstanding this, until we collective publish data on ethnicity pay gaps – alongside action plans to overcome these – our sector may find it difficult to build and sustain trust with our diverse internal and external communities. The Equality (Race and Disability) Bill offers a timely opportunity for our sector to demonstrate its commitment to racial justice.
My fellow vice-chancellors would do well in voicing their support through this government consultation.
In a recent Wonkhe blog, Joe Mintz discussed the challenges of policy impact in social sciences and humanities research.
He highlighted the growing importance of research impact for government (and therefore institutions) but noted significant barriers. These included a disconnect where academics prioritise research quality over early policy engagement and a mutual mistrust that limits research influence on decision-making.
We have recently published a book on research impact that endeavours to explore the challenges of research impact, and these views chime greatly with us. Our motivation for starting the book project were personal. We have carried out a great deal of impactful research and provided support and training for others wishing to engage in impact. However, we wondered why impact seems to be so poorly understood across the sector, and, we had observed, there was a clear fracture between those who wanted to do impactful research, and institutions who wanted to control the process while not really understanding it.
Agenda opposition
There continues to be understandable opposition by some to what has been referred to as “the impact agenda”. One criticism is that impact is something being imposed by government and management that is at odds with the ideology of research. This argument follows that research impact is a market-driven mechanism that pressures academics to demonstrate immediate societal benefits from their research, often at the expense of intellectual freedom and critical inquiry. And a metric driven measurement of research impact may not fully capture the complexity or long-term value of research.
We can certainly empathise with this perspective, but might suggest that this is, in a large part, due to how impact has manifested in a sector that does not really understand what it can be. In our own experiences we have experienced management “advice” that firstly says do not waste your time doing impact, then, once performance-based research funding becomes attached to it, being told it is very important and your impact needs to be “four star”. And then indifference is replaced with interference and attempts to control, to make sure we’re doing it “properly” and making sure it can be monitored.
In trying to develop our understanding, we spoke to 25 “impactful” academics, who had objectively demonstrated that their research has high value impact, and a range of research professionals across the sector. It soon became very clear that our own observations were not outliers for those doing impactful research.
Impact success for those we spoke to came from a personal belief that saw it ingrained in their own research practice – this was something they did because they felt it was important, not because they had been told to. The stakeholders and networks they had, and often spent considerable time building, were their own not their institution’s, and many protected these contacts and networks from institutional interference.
In most cases, interview subjects said that there was little support from their institutions, they just did the work because they felt it was an important part of their research, and this symbiotic work with stakeholders provided further research opportunities. They could see the value of doing impactful research and felt personally rewarded as a result.
And many talked of institutional interference, where there was opposition to what they were doing (“you’re not doing impact properly”) and advised from positions of seniority although perhaps not knowledge or, in some cases integrity. They were instructed to do things more in line with university systems, regardless of how poor they might be. There was a clear dissonance between academic identity and management culture, often informed by an “impact industry” where PowerPoints from webinars are disseminated across institutions with little opportunity for deep knowledge becoming embedded.
Secret sauce
And many spoke of the research management machine, insisting that they engage with central systems so their work could be “monitored” and having many people around them telling them what to do, but offering no support. This support was often as basic as “do more impact” and “give us the evidence now”. In some cases, threats were made to not submit their case studies should they not follow the “correct process”, even when their work was clearly highly impactful. An odd flex for a senior leader, given QR funding goes to the institution, not the academic.
While the research that went into this book probably threw up as many questions as answers, one thing was very clear for this work. If it is to be successful, impact cannot be imposed upon academics or centrally controlled, it must originate from the academic’s community and own identity as a researcher. Telling someone to “do some impact because we need another case study” with a year before a REF submission is not good practice; management needs to take time to understand the research academics are doing and explore together how best to support it.
We are reminded of a comment from one interviewee, who does incredibly interesting and impactful research, and has done for many years. When asked why they do it, they simply said “because I enjoy it and I’m good at it”.
High quality impact case studies come from high quality research and high-quality impact. This is not something that can be gamed or systematised. Academics need to own impact for it to be successful, and institutions need to respect this.
Beginning next week, First Amendment News (FAN) will be moving to Substack. Be sure to sign up and follow us there for future installments!
“No American President has ever before issued executive orders like the one at issue in this lawsuit . . . The instant case presents an unprecedented attack on . . . foundational principles. . . . Here, deciding what process was due to plaintiff is unnecessary, because no process was provided.” — Perkins Coie LLP v. Department of Justice (Dist. Ct., D.C., May 2)
“[T]he Court found that Ms. Rumeysa Ozturk has demonstrated a substantial claim of a violation of due process.” — Ozturk v. Hyde (Dist. Ct., VT, May 16)
Maxim: #1: Vagueness and due process cannot coexist, at least not in any system of constitutional justice worthy of the name.
Maxim #2: The broader the law’s sweep, the greater the likelihood that it was designed to be arbitrarily punitive.
It is undeniable: Many of Donald Trump’s executive orders run wildly afoul of basic tenets of fairness. Time and again, he has ordered his subordinates to enforce orders that are shockingly vague and disturbingly broad. Both in their conception and execution, such orders patently violate the commands of the First, Fifth, and Fourteenth Amendments. And yet, the public and the courts are asked to countenance such abridgments of law in the name of unfettered executive prerogative.
Clarity and precision in lawmaking are fundamental to any system of justice. That call for clarity, which traces back at least to Roman law, finds expression in Montesquieu’s “Spirit of Laws” and William Blackstone’s “Commentaries on the Laws of England.” Laws must be “plainly and perspicuously penned,” is how Blackstone tagged it.
In “FederalistNo. 62,” James Madison condemned those laws that were “incoherent that they cannot be understood.” The idea is rooted in basic fairness, in due process of law. Such a process is especially important in the First Amendment context.
Whether it be in executive orders directed at DEI practices, law firms, universities, libraries, or immigrants, among others, the basic problem of vagueness is the constitutional cancer present in all of them.
As Justice Thurgood Marshall made clear in 1972’s Grayned v. City of Rockford, vagueness offends fairness because (i) it provides no meaningful warning to ordinary persons as to “what is prohibited,” (ii) it provides no “explicit standards” to law enforcement officials, judges, and juries necessary to avoid “arbitrary and discriminatory application,” and (iii) vague laws chill protected speech insofar as the “boundaries of the forbidden areas [are not] clearly marked.”
Justice William Brennan explained the First Amendment importance of that principle in 1963’s NAACP v. Button: “Standards of permissible . . . vagueness are strict in the area of free expression. . . [I]n the area of First Amendment freedoms, the existence of a [vague mandate is] susceptible of sweeping and improper application.”
In the unconstitutional process, lawyers, scientists, librarians, universities, law firms and others are chilled into silence — and that is precisely the point.
The evils of vagueness, among other constitutional wrongs, were thoughtfully identified by federal district court Judge Adam B. Abelson in the recent Maryland District Court case National Association of Diversity Officers in Higher Education v. Trump. In relevant part, Judge Abelson began:
This Court remains of the view that Plaintiffs have shown a strong likelihood of success on the merits of their facial free speech and vagueness claims . . . The Challenged Provisions forbid government contractors and grantees from engaging in “equity-related” work and from “promoting DEI” in ways the administration may consider to violate antidiscrimination laws; they demand that the “private sector” “end . . . DEI” and threaten “strategic enforcement” to effectuate the “end[ing]” of “DEI”; and they threaten contractors and grantees with enforcement actions with the explicit purpose of “deter[ring]” such “programs or principles.”
Judge Adam B. Abelson
Thereafter, he emphasized that the Court was
…deeply troubled that the Challenged Provisions, which constitute content-based, viewpoint-discriminatory restrictions on speech (in addition to conduct), have the inherent and ineluctable effect of silencing speech that has long been, and remains, protected by the First Amendment. And they do so through impermissibly vague directives that exacerbate the speech-chilling aspects of the Challenged Provisions.
To elucidate that point, he added:
Historically, the metaphor used to describe the effect of laws that restrict speech is “chill.” The more apt metaphor here is “extinguish.” Part of the explicit purpose and effect of the Challenged Provisions is to stifle debate — to silence selected viewpoints, selected discourse — on matters of public concern. They forbid government contractors and grantees from engaging in discourse — including speech such as teaching, conferences, writing, speaking, etc. — if that discourse is “related” to “equity. ” And they direct the “private sector” to “end” diversity, to “end” equity, and to “end” inclusion. See J21 Order § 4(b) (directing agencies to “encourage the private sector to end . . . DEI”). “End” is not a mere “chill.” “Deter[rence]” is not a side-effect of the Challenged Provisions; their explicit goal is to “deter” not only “programs” but “principles” — i.e. ideas, concepts, and values. After all, the opposite of inclusion is exclusion; the opposite of equity is inequity; and, at least in some forms, the opposite of diversity is segregation.
Such are but some of the evils rooted in many of Trump’s executive orders. Those affronts to due process and First Amendment principles are so obvious as to render their design intentional (see “Trump’s ‘So what?’ stratagem,” FAN 470).
Trump’s Justice Department defends such lawlessness by procedural obfuscation coupled with political rhetoric and claims of unrestrained executive prerogative. When that fails they take cover by being evasive, as revealed in oral arguments in the Second Circuit case of Ozturk v. Hyde:
The appeals court judges pushed . . . [Department of Justice attorney Drew] Ensign on whether or not the Trump administration believed that both students’ speech was lawful speech.
“We have not taken a position on that,” Ensign told the panel of three judges, saying concerns over where the students’ cases should be heard were more important.
“Help my thinking along,” Judge Barrington D. Parker then said. “Take a position.”
“Your honor, I don’t have authority to take a position on that right now,” Ensign replied.
Drew Ensign
In the unconstitutional process, lawyers, scientists, librarians, universities, law firms and others are chilled into silence — and that is precisely the point.
Consider as well this from an article in The New York Times by Stephanie Saul:
The Trump administration is set to cancel the federal government’s remaining federal contracts with Harvard University — worth an estimated $100 million, according to a letter that is being sent to federal agencies on Tuesday. The May 27 letter [from the U.S. General Services Administration] also instructs agencies to “find alternative vendors” for future services.
The additional planned cuts, outlined in a draft of the letter obtained by The New York Times, represented what an administration official called a complete severance of the government’s longstanding business relationship with Harvard.
The letter is the latest example of the Trump administration’s determination to bring Harvard — arguably the country’s most elite and culturally dominant university — to its knees, by undermining its financial health and global influence. Since last month, the administration has frozen about $3.2 billion in grants and contracts with Harvard. And it has tried to halt the university’s ability to enroll international students.
This episode features a conversation with Cass Sunstein, the Robert Walmsley University Professor at Harvard Law School and former administrator of the White House Office of Information and Regulatory Affairs. His recent working paper, ‘Our Money or Your Life!’ Higher Education and the First Amendment,’ explores the First Amendment constraints on federal funding to American universities.
In the last few weeks, the Trump administration has made several announcements that it is withholding a significant amount of federal funds from specific universities, notably Columbia University and Harvard University, and that those funds will not be released until those universities comply with a set of demands. Harvard received a letter on April 11 demanding changes in Harvard’s governance, faculty hiring practices, student admissions practices, viewpoint diversity among the faculty, and student disciplinary policies, among other things. On May 5, the Secretary of Education sent a letter to Harvard informing the university that the federal government will award it no grants for scholarly research in the future. Reportedly, there is more than $2 billion dollars at stake.
On the podcast we talk through what the Trump administration is doing, what the consequences are for Harvard and other affected universities, and what constitutional issues are raised by the administration’s actions in denying Harvard access to federal research funds. In the process, we get a short course on First Amendment doctrine relating to viewpoint discrimination and unconstitutional conditions.
Trump’s lackey: FCC Chairman Brendan Carr
FCC Commissioner Brendan Carr
“He has . . . abandoned the FCC’s posture as an independent regulator in favor of an openly personal embrace of Trump.”
Four months into his tenure as head of America’s top communications regulator, Brendan Carr appears to be running a Trumpian playbook to transform a long-independent agency.
Immediately after being promoted by President Donald Trump to chair the Federal Communications Commission, on Jan. 20, Carr launched investigations into top media companies, including NPR, PBS and Comcast.
Related
Latest update of Zick’s Executive Orders repository
SCOTUS denies review in middle school ‘two genders’ shirt case
This past Monday the Supreme Court denied review (7-2) in L.M. v. Town of Middleborough. The issue raised in that case was whether school officials may presume substantial disruption or a violation of the rights of others from a student’s silent, passive, and untargeted ideological speech simply because that speech relates to matters of personal identity, even when the speech responds to the school’s opposing views, actions, or policies.
Summary of facts: “In this case, L.M.’s [middle] school prohibited him from wearing a non-obscene, non-vulgar shirt stating, ‘There Are Only Two Genders,’ because the message ‘would cause students in the LGBTQ+ community to feel unsafe.’. The school even banned him from wearing the same shirt on which he covered the words ‘Only Two’ with a piece of tape on which he wrote “CENSORED” so that the message read, ‘There Are [CENSORED] Genders.’”
The petition had been distributed for conference twelve times.
Justice Clarence Thomas wrote a dissent. Justice Samuel Alito also wrote a separate dissent, which in part read:
This case presents an issue of great importance for our Nation’s youth: whether public schools may suppress student speech either because it expresses a viewpoint that the school disfavors or because of vague concerns about the likely effect of the speech on the school atmosphere or on students who find the speech offensive. In this case, a middle school permitted and indeed encouraged student expression endorsing the view that there are many genders. But when L. M., a seventh grader, wore a t-shirt that said “There Are Only Two Genders,” he was barred from attending class. And when he protested this censorship by blocking out the words “Only Two” and substituting “CENSORED,” the school prohibited that shirt as well.
The First Circuit held that the school did not violate L. M.’s free-speech rights. It held that the general prohibition against viewpoint-based censorship does not apply to public schools. And it employed a vague, permissive, and jargon-laden rule that departed from the standard this Court adopted in Tinker v. Des Moines Independent Community School Dist., 393 U. S. 503 (1969).
FBI reopens probe into Dobbs Supreme Court leak
The FBI will launch new probes into the 2023 discovery of cocaine at the White House during President Joe Biden’s term and the 2022 leak of the Supreme Court’s draft opinion overturning Roe v. Wade, a top official announced on Monday. Dan Bongino, a rightwing podcaster-turned-FBI deputy director, made the announcement on X, saying that he had requested weekly briefings on the cases’ progress. . . .
‘So to Speak’ podcast: Heather Mac Donald on Trump & free speech
“[M]y reaction to everything that Trump is doing, and I agree almost across the board with his substantive aims whether it’s with regards to the universities, whether it’s regards to immigration, is what would we feel if the democratic administrations were doing this exact same thing in favor of their values? Everything we’re doing sets a precedent. Again, I acknowledge the precedent has already been set. . . . I’m still very nervous about the government using power because even though I’m not deeply libertarian, I do think that the hope of a neutral arbiter of a government that is restrained by rules that are content-free that are politics-free is one of the biggest yearnings of humanity, at least in the west.” — Heather Mac Donald
Heather Mac Donald discusses the Trump administration’s free speech record amidst its battles with higher ed, mainstream media, law firms, and more.
Mac Donald is a Thomas W. Smith Fellow at the Manhattan Institute. Her most recent book is “When race trumps merit: How the pursuit of equity sacrifices excellence, destroys beauty, and threatens lives.”
Related
Heather Mac Donald, “The White House’s Clumsy Attack on Harvard,” City Journal (April 15) (“The administration is growing ever bolder in its crusade against the institutions responsible for left-wing ideology — whether elite law firms or universities. That crusade is unquestionably justified. Its targets deserve little sympathy. . .”)
2024-2025 SCOTUS term: Free expression and related cases
Cases decided
Villarreal v. Alaniz(Petition granted. Judgment vacated and case remanded for further consideration in light of Gonzalez v. Trevino, 602 U. S. ___ (2024) (per curiam))
Murphy v. Schmitt (“The petition for a writ of certiorari is granted. The judgment is vacated, and the case is remanded to the United States Court of Appeals for the Eighth Circuit for further consideration in light of Gonzalez v. Trevino, 602 U. S. ___ (2024) (per curiam).”)
TikTok Inc. and ByteDance Ltd v. Garland (9-0: The challenged provisions of the Protecting Americans from Foreign Adversary Controlled Applications Act do not violate petitioners’ First Amendment rights.)
Review granted
Pending petitions
Petitions denied
Emergency Applications
Yost v. Ohio Attorney General (Kavanaugh, J., “IT IS ORDERED that the March 14, 2025 order of the United States District Court for the Southern District of Ohio, case No. 2:24-cv-1401, is hereby stayed pending further order of the undersigned or of the Court. It is further ordered that a response to the application be filed on or before Wednesday, April 16, 2025, by 5 p.m. (EDT).”)
Free speech related
Mahmoud v. Taylor (argued April 22 / free exercise case: issue: Whether public schools burden parents’ religious exercise when they compel elementary school children to participate in instruction on gender and sexuality against their parents’ religious convictions and without notice or opportunity to opt out.)
Thompson v. United States (decided: 3-21-25/ 9-0 w special concurrences by Alito and Jackson) (interpretation of 18 U. S. C. §1014 re “false statements”)
Beginning next week, First Amendment News (FAN) will be moving to Substack. Be sure to sign up and follow us there for future installments!
This article is part of First Amendment News, an editorially independent publication edited by Ronald K. L. Collins and hosted by FIRE as part of our mission to educate the public about First Amendment issues. The opinions expressed are those of the article’s author(s) and may not reflect the opinions of FIRE.
In a world obsessed with TikTok trends and digital ad spends, it’s easy to overlook the humble email. Yet, email marketing for universities and other higher educational institutions isn’t just surviving, it’s thriving.
While newer platforms grab headlines, email continues to deliver results where it matters most: student recruitment. In fact, email engagement has surged by a staggering 78% in recent years. That’s a clear signal: email is not just relevant, it’s essential.
Email remains one of the most powerful channels in higher education marketing, and for good reason. By the end of 2025, global email users are projected to reach 4.6 billion, with over 376 billion emails sent daily.
Our targeted email marketing services can help you attract and enroll more students.
Discover how we can enhance your recruitment strategy today!
The ROI speaks for itself: email marketing returns around $36 for every $1 spent, outshining many other channels. Here’s the surprising part. Students want your emails. In a recent survey, more than 68% of students prefer to receive content via email from higher-ed institutions.
But many schools are still doing it wrong. They send the same message to every contact, ignore personalization, and fail to align emails with the student journey. The result? Missed opportunities and low conversions.
This guide will walk you through how to craft student-first, high-converting email campaigns, from audience research to measuring real impact. Ready to turn your inbox into an enrollment engine? Let’s dive in.
Why Email? Why Now?
Let’s start from the very beginning. What is educational marketing? Educational marketing refers to the strategies and tactics used by schools, colleges, and universities to attract, engage, and enroll students. It includes campaigns across digital channels like email, social media, SEO, and paid ads to promote programs and build institutional brand awareness.
From there, we move on to the big question: Is email still relevant in 2025? Absolutely. In fact, 69% of education marketers say email provides a good to excellent ROI, outperforming heavy hitters like social media (55%), display ads (19%), and even SEO (46%).
Why is that?
Because email does three things exceptionally well. It provides a direct line to decision-makers, allows for scalable personalization, and supports long-term engagement without burning through your budget.
But, and this is key, many schools still aren’t tapping into its full potential. Too often, the same message is sent to everyone, without clearly defined audience profiles to guide the way. That’s where opportunity lives, for those willing to do it right.
Know Your Audience: Meet Sophie
Let’s talk about what separates forgettable campaigns from unforgettable ones.
It starts with understanding your audience, not just broadly, but deeply. This is where student personas come into play.
Meet Sophie.
She’s a 30-something international career professional with 3–7 years of experience. Sophie is exploring MBA programs and micro-credentials, driven by career advancement and global networking opportunities. She’s ROI-conscious, skeptical about short courses, and likely found your school via Instagram or Google.
See the difference?
When you write with Sophie in mind, you’re not just blasting content, you’re building trust. She wants to know your credentials are legit. She’s inspired by student success stories. She’s curious about cultural experiences.
So instead of saying, “Join our business program,” try, “Boost your global career with accredited micro-credentials and a community that spans five continents.” Now that’s an email that connects. Now that we’ve seen what a well-developed persona looks like, let’s explore how to apply this kind of insight through segmentation.
Example: McMaster University’s Continuing Education division’s persona-based email drip campaigns for lead nurturing show how each email is tailored to a persona (e.g. career changers in Project Management or Applied Clinical Research) with personalized greetings (“Hi {{FirstName}}”) and program-specific content.
Different students have different interests and needs, so your university email campaign should too.
Segmentation
By dividing your email list into meaningful groups (or “segments”), you can send each group content that truly matters to them. The result? Dramatically better performance.
How to segment effectively? Think about the factors that distinguish your prospective students. Common segmentation angles in higher ed include:
Stage in enrollment journey: Are they brand-new inquiries, applicants, or admitted students? (More on this later.)
Academic interests: What program or major are they interested in? Emails tailored by program (e.g. Engineering vs. Liberal Arts prospects) will highlight different selling points.
Demographics/Location: Is the student international or domestic? High school senior or adult learner? Local or out-of-state? Each group may respond to different messaging.
Behavioural engagement: How have they interacted with your school so far? (Attended a webinar, downloaded a brochure, etc.) Those actions can trigger targeted follow-ups.
Segmenting your list by criteria like these ensures each student gets content that speaks to their specific situation. As a result, your emails feel more relevant, and relevance drives results.
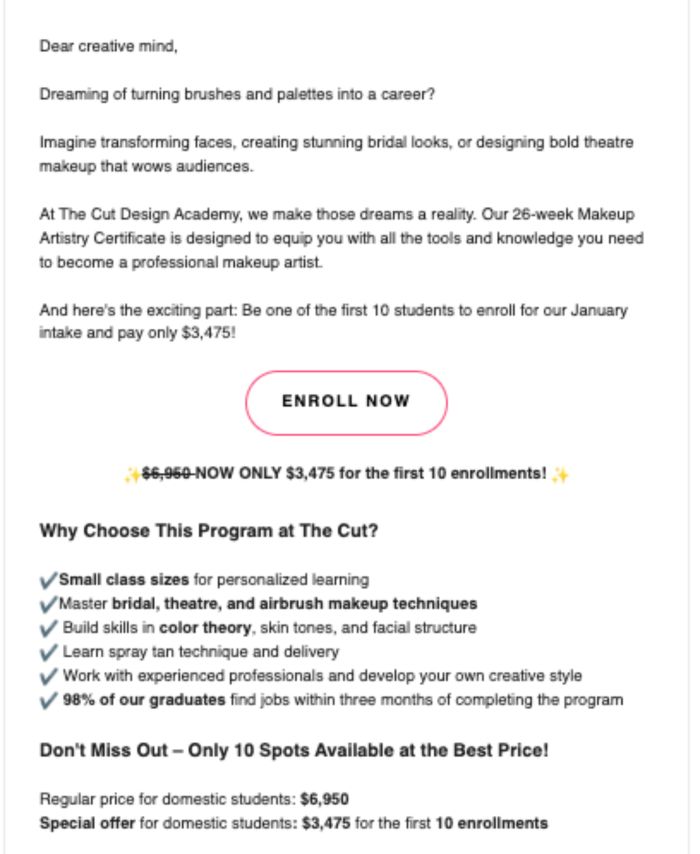
Example: The Cut Design Academy launched a promotional recruitment email targeting prospective students for its January 2025 Makeup Artistry Certificate intake. The campaign focused on driving immediate applications from students close to the decision stage, offering a limited-time tuition discount to accelerate conversions. Framed around an exclusive offer, the email used urgency, clear benefits, and student-focused messaging to stand out. The campaign leveraged personalization through tone (“Dear creative mind”) and clear calls to action, guiding prospects from interest to enrollment with stage-aligned messaging.
Segmented emails consistently outperform generic blasts, leading to stronger engagement, greater relevance, and improved results across the board. Marketers find that tailoring messages to specific audience groups makes campaigns more effective and impactful. The bottom line? When you embrace the diversity of your audience and tailor your messaging accordingly, they’ll reward you with higher engagement.
Let’s say you have a student interested in your Executive MBA. They’ve clicked on emails but haven’t registered for an event. You wouldn’t send them the same message as a high school student in Colombia interested in ESL.
Personalization
Now add personalization on top. If segmentation is about who you’re writing to, personalization is about what and how you communicate to each person. Today’s prospective students expect a personalized touch, and they respond when they get it.
Here’s why: Research shows that emails with personalized content have a 29% higher open rate and a 41% higher click-through rate than non-personalized emails. Simply put, personalization grabs attention. It signals to the student that “this is about you,” cutting through the clutter of impersonal mass communications.
Personalization can be as simple as using the student’s first name in the greeting or subject line – emails with a personalized subject are 29% more likely to be opened, according to Experian. But it goes much deeper than that. Effective enrollment emails often incorporate personal details like the student’s intended major, specific interests, or past interactions.
Let’s Look At Two Examples:
If a prospect has shown interest in your business program, your follow-up emails should reflect that. Highlight business-specific content such as alumni success stories, internship opportunities, and upcoming events related to the program. This reinforces relevance and keeps the student engaged with information they care about.
If a student clicks on a link about financial aid, your next email could focus on scholarships, bursaries, or affordability tips. This kind of targeted follow-up shows that you’re paying attention to their concerns. And students notice this effort.
An EAB survey in 2024 found that 93% of students said receiving a personalized message from a college would encourage them to explore that school further.
That’s an overwhelming majority who are more likely to engage simply because your email spoke directly to their interests or concerns. 71% of students expect personalized interactions from brands (including universities), and 76% get frustrated when they don’t get them. The message is clear: personalization isn’t just a nice touch; it’s expected.
Example: This email from London Business School (LBS), addressed personally to the recipient (“Conor, come and meet some of the people that make LBS unique”), exemplifies effective personalization (using the student’s name and regional relevance) and event-based drip sequencing, reinforcing LBS’s presence and availability as the student prepares to make a decision.
So, how can you infuse personalization into your campaigns? Here are a few proven tactics (think of these as the “little things” that yield big results):
Use dynamic fields: Most email platforms allow you to insert the recipient’s name or other attributes automatically. A subject like “John, here’s info on the Computer Science program you liked” is far more engaging than a generic “Learn about our programs.”
Tailor content to personas: If you’ve segmented by persona or interest, craft the email copy and images to match each segment. A student athlete might get an email highlighting campus sports facilities and team success, whereas a fine arts prospect might see content about your art studios or student exhibits.
Leverage behavioural data: Personalization can also be triggered by what a student does. For instance, “We noticed you started an application – here are the next steps,” or “Thanks for downloading our Nursing Program guide – would you like to attend a nursing info session?” These timely, relevant messages show that you’re paying attention and ready to help.
In a nutshell, how do you develop a marketing strategy for a university? Start by defining clear goals (e.g., increase applications or improve yield), identify target audiences using personas, choose the right channels (email, social, SEO), create tailored content for each stage of the student journey, and measure results regularly to optimize performance.
Align With the Student Journey
A student’s path from curiosity to commitment isn’t linear. Your email marketing strategy shouldn’t be either.
Awareness
This is your digital handshake. Send welcome emails that reflect your institution’s voice: professional, warm, and resourceful. Keep it brief and include CTAs to helpful blog posts, reports, or program videos. The goal here? Spark interest and build trust.
Example: Algonquin College initiated a welcome email campaign targeting newly inquiring students, aimed at supporting the awareness stage of the enrollment funnel. This automated email is sent immediately after a student checks out a program or completes an inquiry form, making it a textbook example of an early-stage drip campaign designed to keep the college top-of-mind and help prospects begin their research journey.
Now that they’re paying attention, it’s time to educate. Share program benefits, tuition details, and testimonials. Even better, offer personalized interaction, like a Q&A session with advisors. Emails at this stage become your student’s research partner.
Example: Miami Ad School implemented a direct and informative follow-up email targeting prospective students who had expressed prior interest in one of its portfolio programs. The message used light personalization and concise formatting to clearly lay out the next steps for engagement. This email served as an early-stage consideration touchpoint designed to convert inquiry-stage leads into applicants.
Here’s where the magic happens, or it doesn’t. Use emails to overcome last-minute doubts, emphasize application deadlines, and make it ridiculously easy to act. Offer a call with an advisor. Include direct application links. This is where you close the loop.
Enrollment
Don’t stop now. Once students say “yes,” keep the momentum going. Celebrate with a warm welcome, then guide them through the next steps: registration links, orientation videos, and community invites. Make them feel like part of something exciting.
The Anatomy of a Winning Email
So what does a high-converting email actually look like?
1. Craft Irresistible Subject Lines
Include first names or program names
Add urgency (“Last Chance!”) or exclusivity (“Just for You”)
Steer clear of spammy ALL CAPS and excessive punctuation
Example: [Alex], Your Journey to an International Career Starts Here
Mobile-first design is a must; 55% of emails are opened on phones
Responsive layouts = higher clicks and happier readers
Stay Out of Spam and In Their Good Books
Even the best content won’t help if it lands in the junk folder. Avoid spam triggers (like “FREE!!!”). Keep your database clean, and follow laws like CAN-SPAM (US), CASL (Canada), and PECR (UK). And yes, always include that unsubscribe link; it builds trust.
Fun fact: The average inbox placement rate is 83%, so there’s room to optimize.
Build Relationships With Drip Campaigns
Think of a drip campaign as a well-timed sequence of nudges. It starts with a thank-you or auto-response after form submission.
Then, over days or weeks, you send emails that deepen interest, event invites, alumni success stories, or a reminder to complete an application. Every email has a purpose. Every message moves the needle.
Track What Really Matters
If you’re only looking at open rates, you’re missing the bigger picture.
Here’s a smarter approach:
Use open rates to gauge subject line effectiveness (aim for 46–50%)
Analyze click-through rates to measure engagement, event invites can hit 15–25%
Most importantly, track conversion rates: Are students applying, booking meetings, or showing up?
The data doesn’t lie. HEM’s insights show that most student bookings happen only after a lead is nurtured, sometimes weeks after their first touchpoint.
Final Thoughts: Your Enrollment Power Tool
We’ve covered a lot of ground, and you might be thinking, “How do I implement all of this?” The key is to view these strategies not as isolated tactics, but as complementary pieces of a holistic email marketing plan.
Segmentation gives you the framework (who gets what), personalization adds the special sauce (making content relevant to each individual), drip campaigns provide the delivery engine (timing and automation), mobile optimization ensures your efforts actually get seen on students’ preferred devices, and enrollment-stage alignment keeps your messaging strategy coherent from start to finish.
Each strategy is powerful on its own, but together they truly transform your email marketing from a simple broadcast tool into an engaging, research-backed recruitment machine.
You’ll be speaking to the right student with the right message at the right time – and that’s a recipe for higher open rates, click-throughs, and conversion to applications and enrollments. Just ask the institutions we discussed: they’ve seen application surges, increased yield, and record enrollments by putting these principles into practice.
To recap, how can colleges increase enrollment? Colleges can boost enrollment by improving lead nurturing (e.g., drip email campaigns), enhancing website conversion, offering personalized communication, streamlining the application process, and using data to better target and engage prospective students.
Done right, email isn’t just part of your marketing mix. It’s the glue that holds your enrollment strategy together.
Our targeted email marketing services can help you attract and enroll more students.
Discover how we can enhance your recruitment strategy today!
Frequently Asked Questions
Question: What is educational marketing?
Answer: Educational marketing refers to the strategies and tactics used by schools, colleges, and universities to attract, engage, and enroll students. It includes campaigns across digital channels like email, social media, SEO, and paid ads to promote programs and build institutional brand awareness.
Question: How do you develop a marketing strategy for a university?
Answer: Start by defining clear goals (e.g., increase applications or improve yield), identify target audiences using personas, choose the right channels (email, social, SEO), create tailored content for each stage of the student journey, and measure results regularly to optimize performance.
Question: How can colleges increase enrollment?
Answer: Colleges can boost enrollment by improving lead nurturing (e.g., drip email campaigns), enhancing website conversion, offering personalized communication, streamlining the application process, and using data to better target and engage prospective students.
From free speech rights and desegregation to gun rights and religious freedoms, civil rights litigation has long been a cornerstone of personal liberty in America. But in February, the Supreme Court issued an opinion that will make it harder for us as Americans to vindicate our constitutional rights when the government violates them.
In Lackey v. Stinnie, a group of Virginia drivers challenged a state law that punished people for failing to pay court fees by automatically suspending their driver’s licenses. The plaintiffs secured a preliminary injunction — a court order issued early in a case to prevent potential harm while it is litigated in full — allowing them to keep their licenses. Virginia did not appeal that ruling, and before the case went to trial, the legislature changed the law and reinstated any licenses that had been suspended under it.
In cases alleging violations of constitutional rights, a federal statute preempts the general rule that litigants pay their own fees and costs by allowing “prevailing” parties to recover attorney’s fees from the government actor who violated their rights. But in this case, the federal district court held the drivers had not in fact “prevailed” given that the case did not progress to a final conclusion, making them ineligible to recover attorney’s fees. This flew in the face of what courts and litigators had understood the law to be for decades.
The case eventually made its way to the Supreme Court to determine what “prevailing” meant in federal law and whether the drivers were entitled to reimbursement. The court, to the disappointment of advocates for civil rights and liberties, held that plaintiffs who do not obtain a final judgment on the merits do not qualify as “prevailing” even if, as with the Virginia drivers, they prevail in getting the government to change the law.
Unlike corporate litigation, civil rights cases rarely involve large financial recoveries. In any event, plaintiffs often seek changes to laws or policies rather than monetary gain. Yet these are vital cases, not just for the individuals involved but for the communities they represent, even if they rarely provide enough financial incentive to make private representation feasible — unless attorneys receive compensation after winning the case.
Congress intended to encourage civil rights litigation by tying fee awards to success, whether through final judgments or preliminary relief. The House Judiciary Committee report on the legislation enacting the attorney’s fees provision noted, “a defendant might voluntarily cease the unlawful practice. A court should still award fees even though it might conclude … that no formal relief, such as an injunction, is needed.” Despite this clear evidence of congressional intent, the court held otherwise.
Importantly, as the court pointed out, Congress has the power to clarify in the statute that attorney’s fees can be awarded before a final judgement on the merits. Congress must do so.
The breadth of amicus briefs submitted in this case — from the ACLU to the Alliance Defending Freedom to the Firearms Policy Coalition — demonstrates that across the ideological spectrum, organizations recognize the critical role awarding attorney’s fees plays in civil rights litigation.
As FIRE noted in its amicus brief to the Supreme Court, “Withholding attorney’s fees from victims of these First Amendment violations would be devastating — not just for them individually, but for access to justice more broadly.”
Congress must enact a simple, clarifying change that will have broad support and ensure all Americans can vindicate their constitutional rights. Justice isn’t free, but we can ensure it remains accessible to all.
The focus of these articles was corruption, fraud and scandal in the Los Angeles Community College District, primarily at Los Angeles Valley College’s Media Arts Department.
A few of these articles summarized.
Erika Endrijonas faces new questions in LACCD fraud | May 2, 2023 |
Pasadena City College President-Superintendent Erika Endrijonas being fired from the institution and trying to get a job at Santa Barbara City College, Mt. SAC, and Los Angeles City College. Endrijonas had been subjected to a vote of no confidence by the Pasadena Academic Senate, Pasadena Full-Time Faculty Union, protests by Part-Time Faculty, and finally the vote to reduce her contract by the newly elected board of trustees.
The article dived into Endrijonas’s tenure at her previous institution – Los Angeles Valley College. Endrijonas was announced in her new role at PCC in December 2018, the same week that a jury in Van Nuys awarded a former LAVC employee $2.9 million jury award for illegal retaliation and abuse. A few months earlier, the Los Angeles Times published a major story about the Valley Academic and Cultural Center – a project meant to be Endrijonas’s crowning achievement – being an alleged massive racketeering scheme.
Further it documented the Media Arts Department the VACC would house had a lengthy history of lawsuits and accreditation complaints against the faculty for not providing the education and training advertised – negating the need for the new building. The building’s approval vote happened in August 2016, the lawsuit happened in 2009, and the Accreditation Complaints happened in June 2016.
Dozen LAVC Cinema Students Narratives challenge Erika Endrijonas’s LACCD Success Story | May 5, 2023 |
This article covered a release of an email thread from a dozen students in 2016 that was ultimately sent to the Accreditation Commission for Junior and Community Colleges in 2016, substantiating that there was widespread fraud in the department. Classes were not scheduled by Department Chair Eric Swelstad, training was not provided, labs were not held, etc . . .
Van Nuys/Los Angeles College Screenwriting Professor Faked Writer’s Guild Membership | May 17, 2023 |
Revealed that LAVC Media Arts Department Chair Eric Swelstad faked his membership in the Writer’s Guild of America – West, and then used it in multiple professional bios.
Los Angeles Valley College perpetuated wage theft against students on Julie Su’s watch | May 19, 2023 |
Documented how Grant Director Dan Watanabe engaged in wage theft against students for two years from 2013 – 2016.
Two Los Angeles Film Professors Bilked Taxpayers Over $3.5 Million Dollars | May 21, 2023 |
Described how LAVC Media Arts Department Founder Joseph Dacursso’s retirement first as Department Chair, then as a full-time faculty in 2012, left Department Chair Eric Swelstad and Arantxa Rodriguez to engage in petty infighting and squabbling that spilled over into scheduling decisions. In short, two faculty members collected six-figure-salaries while putting students in the middle of department in-fighting.
LAVC Omsbudsman Stalked Whistleblowers | August 8, 2023 |
Described how LAVC’s Dean of Students, Annie G. Reed (Goldman) retaliated and stalked students that went to Accreditation, going as far as running a smear campaign that one of them was a potential school shooter. Worse, she began stalking him after he left school – including on social media.
[Image: Annie G. Reed Goldman, Dean of Labor and HR at LACCD]
Further articles questioned where Academic Degrees were given out to students who had not completed Academic classes and criteria, the role of Jo Ann Rivas turned YouTube Personality ‘AuditLA’ who was on the Los Angeles Valley College Citizen’s Building Oversight Committee, whether a number of students with falsified resumes received payments from a Grant as ‘Professional Experts’ etc . . .
The scrubbing of these articles coincided with the formal appointment of Alberto J. Roman as the new Chancellor of the Los Angeles Community College District, following the retirement of disgraced administrator Francisco Rodriguez.
It also came with the publication of two final articles. One about Annie G. Reed’s being named as a Defendant in a lawsuit by former faculty at Los Angeles City College, who came to her about an administrator engaging in illegal behavior – including planting drugs on employees to get them fired.
The second article, probed Los Angeles Valley College Department Chair, Eric Swelstad’s professional bio again and provided evidence that he repeatedly lied and engaged in deceptive advertising and practices for two decades. It provided students who held loans with information about student borrower defenses.
The censorship also came months after Jo Ann Rivas aka AuditLA, herself probed by the articles, launched a barrage of attacks for about a week in January about a former student who had grievance’s against the school. Rivas had previously engaged in a similar barrage in July 2020.
This was not the first time that an attempt was made to censor this news stream.
In 2020, an attempt was made to hack the community news feed account on Twitter/X.com @LACCDW. Then a week before the LACCD Board of Trustees election in November 2020, Twitter suspended the community newsfeed altogether. It was only restored two years later after Twitter’s sale and the re-evaluation of previous suspended accounts.
In a final update – The Valley Academic and Cultural Center, despite having a 2018 completion date, remains unfinished. According to minutes of the LAVC Work Environment Committee Minutes from 2025-05-08;
“The Valley Academic and Cultural Center (VACC) is as of Friday, May 8th, about 80% complete. They are still patching the roof. There are still some critical items like stage protection net.”
Another former Florida lawmaker is stepping into a presidency after the University of West Florida Board of Trustees voted to hire Manny Diaz Jr. in an interim capacity Tuesday.
Diaz, who is currently Florida’s education commissioner, served in Florida’s Senate from 2019 to 2022. The former GOP lawmaker is a close ally of the state’s Republican governor, Ron DeSantis.
The UWF board approved the hire despite the objections of two trustees who raised concerns about transparency and argued that the process of selecting an interim was rushed. UWF’s current president, Martha Saunders, announced her resignation earlier this month after a board member took issue with social media posts from the university dating back several years. Zach Smith, who works for the Heritage Foundation, said he was troubled by actions that included encouraging students to read a book about antiracism and promoting a drag event in 2019.
Both board members and the public questioned Diaz’s qualifications at the meeting.
Trustee Alonzie Scott noted that it was unusual to select an interim without considering internal options and questioned how Diaz was elevated as a sudden candidate without a prior board discussion. He also pressed board chair Rebecca Matthews on whom she spoke with before advancing Diaz as the pick, though she did not offer specifics on those conversations.
“I don’t feel as if I have to run through that list with you today,” Matthews told Scott when he asked whom she had discussed the appointment with before adding it to the board agenda.
Scott also questioned whether the board had violated state sunshine laws.
“I can’t prove that any of us have violated the sunshine guidelines, but I can tell you everything that I read about all the different Florida news outlets, it appears that those decisions were made before this board even had a chance to even discuss. And to me, ma’am, that is a travesty in terms of how we operate,” Scott said, adding the process was “a disservice to the community.”
Matthews defended the hire, noting Diaz’s past work in K-12 education and the State Legislature.
Diaz will formally assume the interim presidency July 14. Despite tapping Diaz as interim, the board will begin a search for its next president, though some trustees argued that naming Diaz instead of an internal candidate to lead UWF would likely suppress the number of applicants.
Of five presidents hired at Florida’s public universities this year (including interim roles), Diaz is one of four who are either former lawmakers or directly connected to the governor’s office. Santa Ono, who was hired as president of the University of Florida on the same day UWF tapped Diaz, is the outlier.
Earlier this week, we announced a new partnership between the University of Michigan and Google to provide free access to Google Career Certificates and Google’s AI training courses for more than 66,000 students across U-M’s Ann Arbor, Dearborn and Flint campuses. These high-demand, job-ready programs are now available through the university’s platform for online and hybrid learning, Michigan Online. The courses and certificates help students to develop in-demand skills in areas like cybersecurity, data analytics, digital marketing, UX design, project management and foundational AI.
We’re both proud graduates of the University of Michigan. Our undergraduate experiences in Ann Arbor were transformational, shaping how we think, who we are and the lives we’ve led. There are countless ways to take advantage of an extraordinary place like U-M. But with the benefit of hindsight, one lesson stands out: Learning how to learn may be the most valuable thing you can take with you.
That has always been true. But it’s becoming more essential in a world where technological change is accelerating and the life span of a “job-ready” skill is shrinking.
A False Choice We Can’t Afford to Make
Today’s learners are navigating a noisy debate: Is a degree still worth it? Should they invest in college—or seek out a set of marketable skills through short-term training?
Too often, this is framed as an either-or choice. But our new partnership underscores the power of both-and.
A college degree is a powerful foundation. And when paired with flexible, high-impact programs like Google Career Certificates, AI Essentials and Prompting Essentials, students are positioned to thrive in a dynamic global workforce. This is not about diluting the value of higher education. It’s about enhancing it—by equipping students with the durable intellectual tools of a university education and the technical fluency to succeed in real-world roles.
The stakes are high. Nearly 70 percent of recent college graduates report needing more training on emerging technologies, while a majority of employers expect job candidates to have foundational knowledge of generative AI. As noted in a New York Times opinion piece by Aneesh Raman, chief economic opportunity officer at LinkedIn, the rise of AI and automation is reshaping the skills required for many jobs, making it imperative for educational institutions to adapt their curricula accordingly. This underscores the importance of integrating practical, technology-focused training into traditional degree programs to ensure graduates are prepared for the modern workforce. The world of work is changing rapidly. Higher education can and must evolve with it.
Rethinking What It Means to Prepare Students for the Future
This partnership is part of a larger effort at the University of Michigan to reimagine what it means to support lifelong learning and life-changing education. Through Michigan Online, U-M students already have access to more than 280 open online courses and series created by faculty in partnership with the Center for Academic Innovation, as well as thousands of additional offerings from universities around the world. These new certificates and AI courses deepen that commitment, creating new on-ramps to opportunity for every student, regardless of background or campus.
Through Google’s flexible online programs, we’ve seen how high-quality, employer-validated training can make a meaningful difference. More than one million learners globally have completed Google Career Certificates, and over 70 percent report a positive career outcome—such as a new job, raise or promotion—within six months of completion. Google’s employer consortium, including more than 150 companies like AT&T, Deloitte, Ford, Lowe’s, Rocket Companies, Siemens, Southwest, T-Mobile, Verizon, Wells Fargo and Google itself, actively recruits from this pool of talent. Google partners with over 800 educational institutions in all 50 states, including universities, community colleges and high schools, to help people begin promising careers in the Google Career Certificate fields.This new partnership extends these opportunities to U-M students to further support career readiness.
By offering accessible, skill-based programs like the Google Career Certificates, we aim to provide additional scaffolding for student success and career readiness, alleviating some of the pressures associated with traditional academic routes and recognizing diverse forms of achievement.
An Invitation to Higher Ed and Higher Ed Ecosystem Leaders
We believe this partnership is a model for how industry and education can come together to create scalable, inclusive and future-forward solutions.
But it’s just one step.
As we reflect on this moment, we invite fellow leaders in higher education, industry and government to ask,
How can your institution better integrate career-relevant skills into the student journey without sacrificing the broader mission of a liberal arts education?
What partnerships or platforms might allow your students to benefit from both a degree and credentials with market value?
In an era defined by AI, how will your institution ensure students are not just informed users of new tools, but thoughtful, responsible and empowered innovators?
How can your institution or organization expand equitable access to high-value learning opportunities that lead to social and economic mobility?
What role should public-private partnerships play in shaping the future of education, work and innovation, and how can we design them for long-term impact?
The path forward isn’t a binary choice. It’s a commitment to both excellence and access, both degrees and skills, both tradition and transformation.
We’re honored to take this step together. And we look forward to learning alongside our students and our peers as we navigate what’s next. In a rapidly shifting higher education environment, we see reason for optimism: opportunities to reimagine student success, forge lasting strategic partnerships and strengthen the bridge between higher education and the future of work.
James DeVaney is special adviser to the president, associate vice provost for academic innovation and the founding executive director of the Center for Academic Innovation at the University of Michigan.

















{kind=link}
{kind=link}