The latest episode of The Key, Inside Higher Ed’s news and analysis podcast, features a discussion between higher ed leaders and IHE editor in chief Sara Custer on how colleges can harness data to better support students.
Speaking at the Student Success 2025 event in November, Courtney Brown, vice president of strategic impact and planning at the Lumina Foundation; Elliot Felix, higher education advisory practice lead at Buro Happold; and Mark Milliron, president of National University, offered unique perspectives to the question of how institutions can be data-driven and student-centered.
“You are not going to serve a student population well unless you do your data work,” said Milliron. The “data work” includes establishing good data governance and data mapping, building a data warehouse, and facilitating data integration across support platforms such as a learning management system and student information systems, he said.
Putting processes and best practice in place is what allowed National to expand its capacity, he said. “I don’t think we could’ve scaled some of the strategies we’ve done unless we did the plumbing work upfront.”
On the question of scale, Felix encouraged institutions to combine their resources to serve more students. “How many institutions are creating their own, bespoke AI policy when they can do [it] as a group or borrow from Educause? There are so many ways to work together to go farther, to go faster.”
While colleges might be teeming with data, Felix encouraged institutions to look at external sources to gain a clearer picture of students’ learning journeys. “I do think more data beyond the walls—employer data, labor market data, employment outcomes—would be really helpful.”
Meanwhile, Brown argued that the needs of the modern-day student are varied and institutions must adapt to their students, rather than students adapting to colleges. Institutions that use data to understand whom today’s students are will be better placed to support their success, she said. “[Students] are parents, they are working, they are financially independent from their own parents. But most policymakers and others don’t think about that. So we need to understand who they are and then transform the system to better serve [them].”
This blog was kindly authored by Martin Lowe, Professor Adrian Wright, Dr Mark Wilding and Mary Lawler from the University of Lancashire, authors of Student Working Lives (HEPI report 195).
The clearest finding of our recent HEPI report, Student Working Lives, was the growing prevalence of paid work among students and its profound impact on their experiences and outcomes.
This trend is not confined to disadvantaged groups; it is now a reality for the majority of students, with the Advance HE and HEPI Student Academic Experience Survey revealing how 68% of students now work during term time. Yet, despite its significance, paid work remains largely absent from regulatory frameworks designed to promote equality of opportunity in higher education.
As the Office for Students (OfS) reviews its approach to access and participation, we argue that paid work should be recognised as a distinct risk on the Equality of Opportunity Risk Register (EORR). Doing so would enable providers to respond more effectively to the challenges students face and ensure that widening participation efforts reflect the realities of modern student life.
A risk-based future for access and participation
Since taking office, the Labour Government has placed widening participation as a central pillar of its higher education agenda. From the introduction of the Lifelong Learning Entitlement to the creation of a new Access and Participation Task and Finish Group, ministers have signalled their determination to open doors to learners from non-traditional backgrounds.
We will reform regulation of access and participation plans, moving away from a uniform approach to one where the Office for Students can be more risk-based.
While this statement attracted less attention than the more headline-grabbing measures on tuition fees and maintenance grants, it represents a potentially transformative change. A risk-based model could allow the OfS to focus on the most pressing barriers to equality of opportunity, provided those risks are accurately identified.
The existing EORR complements this approach. Having been introduced under the leadership of outgoing Director of Fair Access and Participation at the OfS, John Blake, the register has already been widely welcomed by the sector. By identifying factors that threaten access and success for disadvantaged student groups, it enables providers to design interventions tailored to their own context. Rather than simply seeking to address outcome gaps, the EORR encourages institutions to tackle the underlying causes.
However, the register is not static. If it is to remain relevant, it must evolve to reflect emerging challenges. One such challenge is the growing necessity of paid work alongside study, a risk that intersects the financial pressures felt by students but extends far beyond them.
Paid work is more than a financial issue
The current EORR already identifies ‘Cost Pressures’ as a risk, acknowledging that rising living costs can undermine students’ ability to complete their course or achieve good grades. Yet this framing is too narrow on its own. Paid work is not merely a symptom of financial strain; it’s a complex factor that shapes engagement, attainment, and progression into graduate employment.
Our research shows that paid work is a necessity for most students, regardless of background, with average hours worked remaining static across each Indices of Deprivation (IMD) quintile. However, its impact is uneven. Students having to work more than 20 hours per week, those employed in particularly demanding sectors and those balancing caring responsibilities may all face challenges due to increased workload. However each should be supported in different ways.
Figure 1: Likelihood of obtaining a ‘good’ honours degree by work hours
These patterns matter because they influence both academic performance and participation in enrichment activities that support retention and employability. Paid work is a structural feature of student life that can amplify existing inequalities, but present specific nuances depending on the local context.
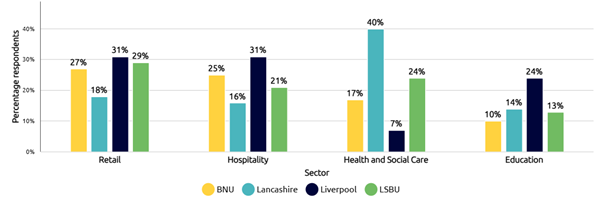
Our analysis highlights how the risks associated with paid work differ across institutions and how regional labour markets shape patterns of student employment. For instance, our survey indicates a higher proportion of students working in health and social care in Lancashire, where the sector represents 15% of total employment. In contrast, Liverpool’s relatively large share of hospitality student workers reflects the sector’s prominence, accounting for around 10% of jobs in the city region. These different contexts can help steer local interventions to reduce risk associated with particular sectors.
Figure 2: Employment by top four sectors (multiple responses accepted)
Recognising paid work as a formal risk would help empower institutions to develop context-sensitive strategies. These might include the crediting of paid work within the curriculum, embedding guidance on employment rights within pastoral support, or designing schedules that accommodate students’ working patterns.
Access and participation – two sides of the same coin
As the OfS explores separating out the “Access” and “Participation” strands of its regulatory framework – as outlined in their recent quality consultation – paid work should feature prominently in supporting both ambitions. Widening access is not simply about opening the door; it is about ensuring wider groups of students see themselves as being part of that experience. For some mature learners, carers, and those with financial dependencies (who may feel excluded by the traditional delivery model of higher education) the support to balance paid work and study is critical.
Ignoring this reality risks undermining the very goals of widening participation. Higher education must adapt to the evolving profile of its students, who increasingly diverge from the outdated stereotype of the full-time undergraduate.
Our recommendation is for the OfS to prioritise paid work as a key aspect of the future of Access and Participation regulation, inserting it as a distinct risk within the Equality of Opportunity Risk Register. Doing so would:
signal its importance as a structural factor affecting equality of opportunity;
enable targeted interventions that reflect institutional and regional contexts;
support innovation in curriculum design, pastoral care, and timetabling;
and promote collaboration between universities, employers, and policymakers to improve job quality and flexibility.
This is not about discouraging students from working. For many, employment provides valuable experience and skills. Instead, it is about recognising that when work becomes a necessity rather than a choice, it can compromise educational outcomes, especially for those already at the margins.
The OfS has an opportunity to lead the sector in addressing one of the most pressing challenges facing students today. By treating paid work as a formal risk, it can help ensure that access and participation strategies are grounded in the lived realities of learners.
As we look to the future, one principle should guide the sector: widening participation does not end at the point of entry. It extends throughout the student journey, encompassing the conditions that enable success. Paid work is now not only part of that journey, but a critical factor.
The department says Palantir was involved in a portal tracking universities’ foreign gifts and contracts.
The American Association of University Professors (AAUP) is publicly expressing concern about the Education Department working with Palantir, a controversial artificial intelligence and data analysis company that serves the U.S. military and Immigration and Customs Enforcement.
The AAUP says it learned of the partnership when FedScoop reported that it noticed a message referencing Palantir on the website foreignfundinghighered.gov Dec. 4. An hour later, the website showed “a login page with the Palantir logo,” and, a couple of hours after that, “the Palantir logo was replaced with an Education Department logo,” the outlet wrote.
Foreignfundinghighered.gov tracks foreign gifts and contracts data for higher ed institutions. If a foreign source provides a college or university more than $250,000 in a year, Section 117 of the Higher Education Act of 1965 requires the institution to report the payment to the federal government.
In an email to Inside Higher Ed, the Education Department described Palantir’s involvement in the past tense. It said Palantir was involved with the foreign funding portal as a subcontractor for Monkton, a company that has long handled privacy and data issues for the Departments of Defense and Homeland Security.
“After soliciting feedback from institutions of higher education, the Trump Administration has upgraded the portal to make it easier for colleges and universities to report their foreign gifts and contracts as required,” Julie Hartman, the Education Department’s press secretary for legal affairs, said in a statement.
The AAUP held a news conference Wednesday raising concern about Palantir’s past work and about critical statements that Palantir leaders Alex Karp and Peter Thiel had made about higher ed.
“We want transparency,” AAUP president Todd Wolfson told reporters. “We want to know what Palantir is doing on this contract and we want to know how much they stand to make.” He said it “seems to be yet another front aimed at surveilling and criminalizing our colleges and universities,” and could indicate a “shift toward treating higher education not as a public good, but as a security threat to be monitored.”
The department didn’t tell Inside Higher Ed how much Palantir is being paid. Hartman said “universities’ clear disclosure and public transparency requirements have been in statute for decades,” adding that the AAUP’s “baseless assertion that the portal is a ‘politicized punitive action’ demonstrates their utter disregard for the rule of law.”
She said, “the Trump Administration is ending the secrecy surrounding foreign dollars and influence on American campuses.” Palantir spokespeople didn’t return Inside Higher Ed’s requests for comment.
One of the unexpected gifts of the pandemic was the clarity it brought. We need to care for ourselves in more substantial and intentional ways if we want to show up fully in the world. For me, that realization sometimes came uncomfortably, as I reflected on just how often I was drained and exhausted. While I supported students through a first-year seminar course called Becoming More Resilient, designed to help students navigate the challenges of the pandemic with a little more ease, I realized I hadn’t yet found a similar framework that resonated with me.
After moving through some challenging seasons of blurred boundaries and little time to focus on my priorities, I found myself drawn to the idea of some kind of daily rhythm that could support my well-being in a more intentional way. Over time, a simple framework began to take shape. It doesn’t solve everything, but it gently reminds me of what helps me feel more whole, more present, and more grounded in my life and work.
When I integrate this structure into my life, I’m not just more productive, I show up more fully for my students, my colleagues, and myself. What follows is the framework I’ve come to rely on: five key pillars of care and support that help me stay grounded and energized.
Emotional Resilience: Boundaries, Self-Compassion, and Self-Awareness
Emotional resilience isn’t about pushing through and bouncing back. For me, it’s about learning how to pause and listen to what I need. I’ve started using a simple journaling practice to reflect on my emotional highs and lows each week, which helps me notice patterns I might otherwise miss. I’ve also learned to be more deliberate with boundaries. I keep email and letter templates for common situations that tend to drain me, and I am generous with my office/student hours, which then allows me to close my door at other times during the week without guilt. When things feel especially hard, I’ve come to rely on a few quiet moments of self-compassion, reminding myself that doing enough is different from doing everything. I have sticky notes of mantras that I shared with students during the pandemic that I appreciate now, like “progress over perfection” and “I am enough.” While I don’t practice these as consistently as I would like, when I do, they’ve helped me show up with less stress and more grace.
How to Get Started:
Practice simple, kind ways to say no like: “It sounds like a wonderful opportunity but I’m at full capacity.”
Physical Well-being: Movement, Nutrition, Sleep
Physical wellbeing was the first thing I let slide when work became overwhelming, but I’ve slowly started to shift that pattern. I’ve learned that even small amounts of movement, like a walk on campus–bonus points for connecting with a colleague while walking–or even standing for online meetings, can reset my energy. I’ve also begun paying more attention to how I nourish myself during the day. I embraced intermittent fasting and rarely ate until 2 pm. This regular practice has many benefits, but it likely spiked my cortisol levels. Now I keep fruit, nuts, and simple salads on hand and a thermos of hot water for tea. And I’m finally protecting my sleep with a bit more intention: shutting down my screens earlier, winding down with a book, and starting my day in the early morning sun to reset my circadian rhythm. I don’t do it perfectly, but when I take care of my body, everything else feels more manageable.
How to Get Started:
Plan and pack some healthy foods to keep you fueled throughout your day. Limit the vending machine to emergencies.
Finding ways to truly relieve stress—rather than just powering through it—has become one of the most important parts of my routine. My partner and I start our day with a morning meditation. This sacred time seems to create more space in my brain for the day ahead. I’ve also started building in short moments of stillness throughout the day, even if it’s just a few deep breaths. These tiny pauses help me reset, especially when the day starts to feel like a blur. I add some rejuvenating activities on my calendar: walking with my son, working in the garden, rolling out my Yoga mat. All are free and simple. Relaxation doesn’t always mean doing nothing; sometimes it’s music, journaling, or simply giving myself permission to stop working before I’m completely depleted. These small choices remind me that I’m allowed to move through my day with more ease.
How to Get Started:
Add a three-minute reset to your morning. Set the timer for three minutes, close your eyes and simply breath, allowing all thoughts to float by like clouds.
Meaningful Living: Joy, Connection, Creativity
I’ve come to realize that for me, meaningful living means making space for the things that fuel me—joy, creativity, and connection. It’s easy to let these fall to the bottom of the list when deadlines pile up, but when I protect them, everything else feels more doable. I carve out small pockets of time to do something creative and joyful like cooking something new, writing for myself, going to a farmers’ market or exploring a new bookstore or town. I try to stay connected to the people who matter, even if it’s just a quick check-in or a shared laugh. I also notice that I enjoy the time that I spend with my students when I am not overwhelmed with other aspects of my job. The classroom can be a joyful, connected space filled with creativity when we allow ourselves to be fully present and engaged. These moments remind me that life is about way more than productivity. These experiences bring me back to what I value.
How to Get Started:
Chart your best moment of the day in a journal. Soon you will have 365 best moments! I love this practice because even the worst days have a best moment.
Time and Energy Protection: Prioritize, Say No with Kindness, Focus
Saying no with kindness has been a practice, one that allows me to be more intentional about where my energy goes. I have many passions so saying no sometimes feels like a missed opportunity. The more I am aligned with my priorities and core values, the more I can empower myself to decline offers. I started a new practice in which I named one focus for the day. For example, I may be teaching a class on Wednesday, but my main focus is to revise an article, grade papers, or attend a complex committee meeting on that day. I give myself a high five for completing the focus and give myself grace if some loose ends remain from the day. One area where I need work is guarding space for creative work, the kind that needs unhurried thinking and a little room to breathe. It’s not always easy, but I recently had an epiphany about how focusing on what matters and saying no to all the rest allows me to bring my best self to my work.
How to Get Started:
Name your focus of the day. Prepare to tackle just that one thing well. Give yourself grace for whatever remains unfinished.
These practices didn’t come to me all at once; they’ve taken shape slowly, over time, through trial and error, losses and wins. What I’ve found is that caring for myself in these intentional ways isn’t separate from my work as a professor, it’s what makes the work sustainable, meaningful, and even joyful. By tending to the five pillars of the framework, I’ve created a rhythm that helps me show up more fully, celebrating small wins along the way. It’s not a perfect system, but the structure that it provides makes my life better. And in this season of my life and career, that feels like enough.
Julie Sochacki is a clinical associate professor who has worn several hats at her university over the past few years including interim director of the university’s teaching center, associate dean of student academic services, and most recently, writing director. Check out her Substack with colleague, Patrick Allen: The Inspired Teaching Podcast.
One of the unexpected gifts of the pandemic was the clarity it brought. We need to care for ourselves in more substantial and intentional ways if we want to show up fully in the world. For me, that realization sometimes came uncomfortably, as I reflected on just how often I was drained and exhausted. While I supported students through a first-year seminar course called Becoming More Resilient, designed to help students navigate the challenges of the pandemic with a little more ease, I realized I hadn’t yet found a similar framework that resonated with me.
After moving through some challenging seasons of blurred boundaries and little time to focus on my priorities, I found myself drawn to the idea of some kind of daily rhythm that could support my well-being in a more intentional way. Over time, a simple framework began to take shape. It doesn’t solve everything, but it gently reminds me of what helps me feel more whole, more present, and more grounded in my life and work.
When I integrate this structure into my life, I’m not just more productive, I show up more fully for my students, my colleagues, and myself. What follows is the framework I’ve come to rely on: five key pillars of care and support that help me stay grounded and energized.
Emotional Resilience: Boundaries, Self-Compassion, and Self-Awareness
Emotional resilience isn’t about pushing through and bouncing back. For me, it’s about learning how to pause and listen to what I need. I’ve started using a simple journaling practice to reflect on my emotional highs and lows each week, which helps me notice patterns I might otherwise miss. I’ve also learned to be more deliberate with boundaries. I keep email and letter templates for common situations that tend to drain me, and I am generous with my office/student hours, which then allows me to close my door at other times during the week without guilt. When things feel especially hard, I’ve come to rely on a few quiet moments of self-compassion, reminding myself that doing enough is different from doing everything. I have sticky notes of mantras that I shared with students during the pandemic that I appreciate now, like “progress over perfection” and “I am enough.” While I don’t practice these as consistently as I would like, when I do, they’ve helped me show up with less stress and more grace.
How to Get Started:
Practice simple, kind ways to say no like: “It sounds like a wonderful opportunity but I’m at full capacity.”
Physical Well-being: Movement, Nutrition, Sleep
Physical wellbeing was the first thing I let slide when work became overwhelming, but I’ve slowly started to shift that pattern. I’ve learned that even small amounts of movement, like a walk on campus–bonus points for connecting with a colleague while walking–or even standing for online meetings, can reset my energy. I’ve also begun paying more attention to how I nourish myself during the day. I embraced intermittent fasting and rarely ate until 2 pm. This regular practice has many benefits, but it likely spiked my cortisol levels. Now I keep fruit, nuts, and simple salads on hand and a thermos of hot water for tea. And I’m finally protecting my sleep with a bit more intention: shutting down my screens earlier, winding down with a book, and starting my day in the early morning sun to reset my circadian rhythm. I don’t do it perfectly, but when I take care of my body, everything else feels more manageable.
How to Get Started:
Plan and pack some healthy foods to keep you fueled throughout your day. Limit the vending machine to emergencies.
Finding ways to truly relieve stress—rather than just powering through it—has become one of the most important parts of my routine. My partner and I start our day with a morning meditation. This sacred time seems to create more space in my brain for the day ahead. I’ve also started building in short moments of stillness throughout the day, even if it’s just a few deep breaths. These tiny pauses help me reset, especially when the day starts to feel like a blur. I add some rejuvenating activities on my calendar: walking with my son, working in the garden, rolling out my Yoga mat. All are free and simple. Relaxation doesn’t always mean doing nothing; sometimes it’s music, journaling, or simply giving myself permission to stop working before I’m completely depleted. These small choices remind me that I’m allowed to move through my day with more ease.
How to Get Started:
Add a three-minute reset to your morning. Set the timer for three minutes, close your eyes and simply breath, allowing all thoughts to float by like clouds.
Meaningful Living: Joy, Connection, Creativity
I’ve come to realize that for me, meaningful living means making space for the things that fuel me—joy, creativity, and connection. It’s easy to let these fall to the bottom of the list when deadlines pile up, but when I protect them, everything else feels more doable. I carve out small pockets of time to do something creative and joyful like cooking something new, writing for myself, going to a farmers’ market or exploring a new bookstore or town. I try to stay connected to the people who matter, even if it’s just a quick check-in or a shared laugh. I also notice that I enjoy the time that I spend with my students when I am not overwhelmed with other aspects of my job. The classroom can be a joyful, connected space filled with creativity when we allow ourselves to be fully present and engaged. These moments remind me that life is about way more than productivity. These experiences bring me back to what I value.
How to Get Started:
Chart your best moment of the day in a journal. Soon you will have 365 best moments! I love this practice because even the worst days have a best moment.
Time and Energy Protection: Prioritize, Say No with Kindness, Focus
Saying no with kindness has been a practice, one that allows me to be more intentional about where my energy goes. I have many passions so saying no sometimes feels like a missed opportunity. The more I am aligned with my priorities and core values, the more I can empower myself to decline offers. I started a new practice in which I named one focus for the day. For example, I may be teaching a class on Wednesday, but my main focus is to revise an article, grade papers, or attend a complex committee meeting on that day. I give myself a high five for completing the focus and give myself grace if some loose ends remain from the day. One area where I need work is guarding space for creative work, the kind that needs unhurried thinking and a little room to breathe. It’s not always easy, but I recently had an epiphany about how focusing on what matters and saying no to all the rest allows me to bring my best self to my work.
How to Get Started:
Name your focus of the day. Prepare to tackle just that one thing well. Give yourself grace for whatever remains unfinished.
These practices didn’t come to me all at once; they’ve taken shape slowly, over time, through trial and error, losses and wins. What I’ve found is that caring for myself in these intentional ways isn’t separate from my work as a professor, it’s what makes the work sustainable, meaningful, and even joyful. By tending to the five pillars of the framework, I’ve created a rhythm that helps me show up more fully, celebrating small wins along the way. It’s not a perfect system, but the structure that it provides makes my life better. And in this season of my life and career, that feels like enough.
Julie Sochacki is a clinical associate professor who has worn several hats at her university over the past few years including interim director of the university’s teaching center, associate dean of student academic services, and most recently, writing director. Check out her Substack with colleague, Patrick Allen: The Inspired Teaching Podcast.
AI isn’t the only reason new graduates can’t get a job, but it is changing the job market they’re entering. Economic uncertainty and a surplus of college graduates are contributing far more to high unemployment among young degree holders than job-thieving robots.
A recent Federal Reserve analysis showed that the unemployment gap between high school and college graduates has been narrowing since the 2008 recession and now sits at around 2.5 percentage points, down from an average of five percentage points from roughly the 1980s to early 2000s. The National Association of Colleges and Employers’ 2026 Job Outlook Survey found that employers expect hiring for the Class of 2026 to remain flat. Next year’s job market likely won’t improve for college graduates.
But even though huge corporations like Amazon, Target and Klarna say they are laying off tens of thousands of employees because of AI, they do not represent the majority of employers. Like the rest of us, most companies are still figuring out AI. In the NACE survey, nearly 59 percent of employers said they are not planning to or are unsure whether they’ll augment entry-level jobs with AI, and just 25 percent said they’re currently discussing it.
Meanwhile, in a recent Substack post, economist and CUNY Graduate Center professor Paul Krugman argued it’s too soon for AI to have such a drastic impact on unemployment for college-educated workers; instead, he blamed the crummy job market on tariffs, uncertainty in the economy and even DOGE cuts flooding the job market with laid-off, educated federal workers.
These market challenges coincide with intensifying pressure from the federal government and the general public for colleges to show that their degrees are valuable. Just this week, the Department of Education rolled out a new feature in the Free Application for Federal Student Aid alerting students if the institutions they’ve applied to produce graduates who earn less than people with just high school degrees.
While the state of the economy is out of higher education’s control, institutions should heed employer calls for graduates with real-world experience. Career-ready students will be able to adapt to the evolving world of work and see that their degrees are worth the investment. The most promising response is for colleges to embrace experiential learning.
A survey of employers released this week by the American Association of Colleges and Universities showed that college graduates who are proficient in applying knowledge to the real world and who understand teamwork are the most likely to be hired. Students agree: They cited paid internships and building stronger connections with employers as the top things colleges can do to help them get career-ready.
Focusing on work-based learning will achieve two things: get students the real-world experience employers demand and set them up for long-term economic success. The college premium may be eroding, but it persists. And while high school graduates might be getting jobs more quickly than recent college graduates, those with degrees stay employed longer once they do find jobs.
Regional economies will benefit from graduates with real-world experience, too. Students who participate in internships or apprenticeships are more likely to find local jobs after they graduate. Studies even show that underemployed graduates, those working jobs that don’t require a college degree, land in roles with higher intrinsic value—think less physical labor, more respectful treatment and better opportunities for skill development.
Some institutions are further along than others. A program at Harvey Mudd College pairs undergraduates early in their degrees with alumni around the country for summer job shadows. Others target career support to individual student groups, such as neurodiverse students and veterans. Virginia recently announced a partnership with Handshake to provide each student at a public institution at least one form of work-based learning in an effort to keep talent in the state. And the Delaware Workforce Development Board gave the University of Delaware’s Lerner College of Business and Economics a grant to create a yearlong co-op program with businesses across the state, partly to “keep homegrown talent here in Delaware,” the chair of the board said.
The economic forces impacting the job market aren’t going away, and neither is AI’s transformational influence on how work gets done. The solution for colleges is simple: Students need real-world experience and employers are explicit about wanting to hire graduates who have it. Colleges must start building employer relationships and embedding experiential learning into the curriculum now. The institutions that get it right will be the ones whose graduates never question the value of their degree.
Sara Custer is editor in chief at inside Higher Ed.
In September, Science Minister Lord Vallance announced a pause to developing REF 2029 to allow REF and the funding bodies to take stock. Today, REF 2029 work resumes with a refreshed focus to support a UK research system that delivers knowledge and innovation with impact, improving lives and creating growth across the country.
Research England has undertaken a parallel programme of work during the pause, intended to deliver outcomes that align with Government’s priorities and vision for higher education as outlined in the recently published Post-16 Education and Skills white paper. Calling this a pause doesn’t reflect the complexity, pace and challenge faced in delivering the programme over the last three months.
Since September, we have:
explored the option of baseline performance in research culture being a condition of funding
considered how our funding allocation mechanisms in England could be modified to better reward quality, as part of our ongoing review of Strategic Institutional Research Funding (SIRF)
fast-tracked existing activity related to the allocation of mainstream quality-related research funding (QR).
developed our plans to consider the future of research assessment.
Over the last three months to progress this work, we’ve engaged thoughtfully with groups across the English higher education and research sector, as well as with the devolved funding bodies, to help us understand the wider context and refine our approaches. Let me outline where we’ve got to – and where we’re going next – with the work we’ve been doing.
Setting a baseline for research cultures
Each university, department and team are unique. They have their own values, priorities and ways of working. I therefore like to think of ‘research cultures and environments’, using the term in plural, to reflect this diversity. The report of the REF People, Culture and Environment pilot, also published today, confirms that there is excellent practice in this area across the higher education sector. REF 2029 offers an opportunity to recognise and reward those institutions and units that are creating the open, inclusive and collaborative environments that enable excellent research and researchers to thrive.
At the same time, we think there are some minimum standards that should be expected of all providers in receipt of public funding. To promote these standards, we will be strengthening the terms and conditions of Research England funding related to research culture. In the first instance, this will mean a shift from expecting certain standards to be met, to requiring institutions to meet them.
We are very conscious not to increase burden on the sector or create unnecessary bureaucracy. This will only succeed by engaging closely with the sector to understand how this can work effectively in practice. To this end, we will be engaging with groups in early 2026 to establish rigorous standards that are relevant across the diversity of English institutions. As far as possible, we will use existing reporting mechanisms such as the annual assurance report provided by signatories to the Research Integrity Concordat. While meeting the conditions will not be optional, we will support institutions that don’t yet meet all the requirements, working together and utilising additional reporting to help with and monitor improvements. And because research cultures aren’t static, we will evolve our conditions over time to reflect changes in the sector.
This will lead to sector-wide improvements that we can all get behind:
support for everyone who contributes to excellent and impactful research: researchers, technicians and others in vital research-enabling roles, across all career stages
ensuring research in England continues to be done with integrity
ensuring that is also done openly
strengthening responsible research assessment.
Our next steps are to engage with the sector and relevant groups as part of the process of making changes to our terms and conditions of funding, and to establish low-burden assurance mechanisms. For example, working as part of the Researcher Development Concordat Strategy Group, we will collectively streamline and strengthen the concordat, making it easier for institutions to implement this important cross-sectoral agreement.
These changes will complement the assessment of excellent research environments in the REF and the inspiring practice we see across the sector. Championing vibrant research cultures and environments is a mission that transcends the REF — it’s the foundation for maintaining and enhancing the UK’s world-leading research, and we will continue to work with the devolved funding bodies to fulfil the mission.
Modelling funding mechanisms
The formula-based, flexible research funding Research England distributes to English universities is crucial to underpinning the HE research landscape, and supporting the
financial sustainability of the sector. We are aware that that this funding is increasingly being spread more thinly.
As part of the review of strategic institutional research funding (SIRF), we are working to understand the wider effectiveness of our funding approaches and consider alternative allocation mechanisms. Work on this review is continuing at speed. We will provide an update to the sector next year on progress, as well as the publication of the independent evaluation of SIRF, anticipated in early 2026.
Building on this, we have been considering how our existing mechanisms in England could be modified to better reward quality of research. This work looks at how different strands of SIRF – from mainstream QR to specialist provider funding – overlap, and how that affects university finances across English regions and across institution types. We are continuing to explore options for refining our mainstream QR formula and considering the consequences of those different options. This is a complex piece of work, requiring greater time and attention, and we expect next year to be a key period of engagement with the sector.
The journey ahead
While it may seem early to start thinking about assessment after REF 2029, approaches to research assessment are evolving rapidly and it is important that we are able to embrace the opportunities offered by new technologies and data sources when the moment comes. We have heard loud and clear that early clarity on guidance reduces burden for institutions and we want to be ready to offer that clarity. A programme of work that maximises the opportunity offered by REF 2029 to shape the foundation for future frameworks will be commencing in spring 2026.
Another priority will be to consider how Research England as the funding body for England, and as part of UKRI, can support the government’s aim to encourage a greater focus on areas of strength in the English higher education sector, drawing on the excellence within all our institutions. As I said at the ARMA conference earlier in the year, there is a real opportunity for universities to identify and focus on the unique contributions they make in research.
The end of the year will provide the sector (and my colleagues in Research England and the REF teams) with some much-needed rest. January 2026 will see us pick back up a reinvigorated SIRF review, informed by the REF pause activity. We will continue to refine our research funding and policy to – as UKRI’s new mission so deftly puts it – advance knowledge, improve lives and drive growth.
The One Big Beautiful Bill Act is the biggest shake-up to federal higher education policy in more than a decade. And while the bill passed on partisan lines, implementing it to maximize student success and postsecondary value requires real bipartisan cooperation. With negotiated rule making under way, and 2026 implementation deadlines looming, a new deep-dive report from Inside Higher Ed, “After Reconciliation: Higher Ed Reform and Where Left–Right Collaboration Matters Most,” looks at conservative, progressive and institutional priorities and perspectives on three key areas of OBBBA: institutional accountability for student outcomes; new loan limits and payment reforms; and changes to the Pell Grant program, including the introduction of Workforce Pell.
Join the Discussion
On Wednesday, Jan. 21 at 2 p.m. Eastern, Inside Higher Ed will host a live webcast discussion on the report and OBBBA’s impact on higher education. Register for that here. Download the free report here.
Despite clear differences of opinion on various areas of the bill, many experts agree on the need for accountability, limits on excessive graduate debt and support for high-value training programs.
“The underlying principles here of stronger accountability for financial outcomes, of reining in excessive borrowing, especially in the graduate education space—those are bipartisan priorities that have been expressed for a long time,” says Michelle Dimino, director of education programs at the think tank Third Way. “These are conversations that we have been having in the higher education reform space for the last decade and beyond.”
Common concerns also emerge around the tight timeline for adoption, the data infrastructure to support changes, aligning earnings regulations, handling repayment plan transfers with care, protecting the Pell Grant budget and more. Another challenge: execution by an Education Department in transition.
“After Reconciliation: Higher Ed Reform and Where Left–Right Collaboration Matters Most” was written by Ben Upton. The independent editorial project is supported by Arnold Ventures.
You spent all of sophomore year perfecting your study system. Organized, color-coded flashcard, easy to review: it worked beautifully. Then junior year hit, and suddenly those same study methods feel completely useless when you’re preparing for exams.
What happened? Well, here’s what didn’t happen: You didn’t suddenly forget how to study. And you didn’t suddenly get ignorant.
What did happen is that something leveled up, but your system didn’t level up with it.
As a study skills expert with 20 years of teaching experience, I see this all the time. Students come to me frustrated because a method that used to work has stopped working. They assume they’re doing something wrong, or that they just need to “try harder.”
But the reality is usually much simpler: their system stopped working for a very specific, identifiable reason.
An important note before we go further: This post assumes you’re starting with a legitimate study system, meaning you’re already using active recall and spaced repetition as your foundation.
If you’re re-reading notes, highlighting textbooks, or cramming the night before, those aren’t study systems that “stopped working”: they’re passive methods that never worked in the first place. Active recall (testing yourself) and spaced repetition (spreading study sessions over time) are non-negotiables at every level. This post is about what happens when you’re using those evidence-based methods correctly, but they still feel less effective than they used to be.
In this post, I’m breaking down the five main reasons legitimate study systems fail, and what each signal means. Understanding why your system stopped working is the first step to figuring out what to do next.
Why Your Study Systems Don’t Work Anymore
Below are the five primary reasons why your “good” study systems stopped working. You may find that one, two, or all apply to your situation.
1. Developmental Transitions: You’ve Leveled Up, But Your System Hasn’t
Academic demands don’t just get “harder” as you progress through school: they fundamentally change. What worked in high school might be perfectly executed active recall, but if you’re still using high school-level active recall in college, you’re bringing the right tool at the wrong intensity.
As you move to harder courses or higher levels (from high school to college, for example), the following three changes happen:
1. The cognitive demand increases.
High school tests often reward memorization and recall. College exams (and especially graduate-level work) require synthesis, application, and critical analysis.
In other words, your flashcards might have been perfect for memorizing vocabulary or formulas, but now you need to apply those concepts to novel situations or synthesize information across multiple sources.
2. The external structure disappears.
In high school, teachers often build review into class time, tell you exactly what to study, and remind you about deadlines.
But in college, professors expect you to figure out what’s important, create your own review schedule, and manage longer-term projects without check-ins. Your study system (and you!) now has to do the work your teacher used to do.
3. The pace accelerates.
You might have had a week to prepare for a high school test covering two chapters. In college, you might have three days to prepare for an exam covering six weeks of material across lectures, readings, and discussions.
What This Signal Means and What to Do:
Your active recall methods aren’t wrong; they’re just not scaled to match your current demands. Here’s how to level up your study methods:
1. Extend your spaced repetition timeline.
If you used to start studying three days before a test, you now need to start a week or two out. If you used to start a week out, now start two weeks out. Spread your active recall sessions over more days to account for the increased volume of material.
2. Add more complex practice problems.
Don’t just test yourself on definitions — test yourself on application. Look for practice problems at the end of textbook chapters, old exams from your professor (just ask; they may say no, but it’s worth asking), or create your own “what if” scenarios that force you to apply concepts in new ways.
3. Create study materials that force higher-order thinking.
Instead of flashcards that ask “What is X?”, create questions like “How does X relate to Y?” or “What would happen if X changed?” Write practice essay prompts for yourself. Teach the concept out loud as if explaining it to someone who’s never taken the class. Make Venn diagrams.
2. The Invisible Skill Gap: Your Classes Require Skills You Don’t Have Yet
Many teachers assume you have certain skills that you were never actually taught, especially executive function skills like planning, prioritizing, and self-monitoring. Or metacognitive skills like knowing how to study effectively or recognizing when you actually understand something versus when you just think you do.
These invisible skills weren’t required at earlier academic levels, so your study system didn’t need to account for them. But now they’re essential, and their absence is why it feels like your system is failing. (Again, it’s not that your system is failing…it’s just that it needs to scale up.)
Examples of invisible skill gaps:
1. Backwards planning (aka reverse engineering).
In high school, most assignments were short-term: read chapter 3, answer the questions, done. In college, you have research papers due in six weeks, and you need to break that down into smaller tasks and deadlines yourself. Your planner worked before because you just wrote down what the teacher told you to do. Now you need a system that helps you create your own deadlines.
2. Managing competing priorities.
When you had five classes with predictable homework each night, a simple to-do list was often enough. Now you have fewer classes but longer-term projects, exams on completely different schedules, and activities outside of school. You need a system that helps you see the big picture and make strategic decisions about where to focus your time.
3. Critical reading vs. just reading.
You could sometimes get away with passive reading in high school because teachers reviewed everything in class. Now you’re expected to extract key concepts, identify arguments, and connect ideas across readings on your own. Your old annotation system captured facts, but didn’t require you to truly thinkanalytically about the material.
What This Signal Means and What to Do About It:
You’re simply discovering skills you haven’t developed yet. Here are what skills to focus on:
1. Build in backwards planning.
For any assignment longer than a week, break it into smaller milestones with self-imposed deadlines. Put those milestones in your planner or calendar just like you would “real” deadlines.
2. Use a priority system, not just a task list.
Add a way to mark tasks as high/medium/low priority, or use a system that helps you see what’s due soon versus what’s due later. This helps you make decisions when everything feels urgent.
3. Add metacognitive check-ins to your study sessions.
After each study session, ask yourself: “Could I teach this to someone else right now?” or “What am I still confused about?” This self-awareness helps you catch gaps before the exam does.
3. Capacity vs. Method: Sometimes It’s More About What You Can Handle, Not How You Handle It
Sometimes a study system stops “working” not because there’s anything wrong with the method, but because you’re operating beyond your capacity. Maybe you’re maxed out and overloaded and don’t even know it. (Or maybe you do know, but you just know what to do about it.)
When you’re at capacity, even the most effective active recall methods will feel impossible to execute. You’ll cut corners, skip steps, or give up on the whole thing simply because you don’t have the bandwidth to figure things out.
Signs you’re at capacity:
Everything feels hard, even methods you know should work or that used to work
You’re consistently sacrificing sleep to keep up
You’re skipping meals or exercise because there’s “no time”
You feel anxious or overwhelmed most days
You’re behind in multiple classes, not just one
Helpful Resource: Are You Doing Too Much? Link
When you’re in this state of maxed-out capacity, the problem isn’t your study technique. It’s that you can’t execute because you’re exhausted.
What This Signal Means and What to Do About It:
Before you overhaul your entire study system, honestly evaluate whether you need to reduce your load or increase your support. Here’s what to consider:
1. Audit your commitments.
List everything you’re doing: classes, work hours, extracurriculars, family obligations. Is anything optional that you could step back from, even temporarily? Sometimes “doing less, better” is the answer. (Inside SchoolHabits University, I have students complete an Activity Inventory, a self-assessment that provides concrete, measurable evidence about whether they’re overcommitted or undercommitted. This kind of objective data can help you see the reality of your schedule instead of just feeling overwhelmed.)
Look at your course load specifically. Are you taking too many credits? Are you taking multiple high-demand classes in the same semester? Sometimes the best study system is strategic course selection.
2. Increase support, not just effort.
This might mean going to office hours, hiring a tutor, joining a study group, or talking to a counselor about time management or stress. It might also mean having honest conversations with family about what you can realistically handle.
No study system, no matter how evidence-based, can compensate for chronic overload. If you’re consistently operating at 110% capacity, something has to give.
4. You Cling to What You Know Because You’re Nervous to Try Something New
This one is more psychological than practical, but it’s just as important to consider: sometimes students keep using a system they know isn’t working because changing it feels even scarier than failing with it.
Familiar failure has a strange comfort to it. At least you know what to expect. At least you know it’s the system’s fault and not yours. At least you don’t have to risk trying something new and discovering it doesn’t work either. These are all super uncomfortable realities to accept.
Below are some mental traps that you might be falling into. Read them with an open mind.
1. “At least I know what to expect.”
Even if your current system produces mediocre results, those results are predictable. Changing your system means uncertainty, and uncertainty feels risky when grades are on the line.
2. The sunk cost fallacy.
“I spent so much time building this planner system / making these flashcards / organizing my notes this way. I can’t just abandon it now.” Yes, you can. Time already spent is gone, whether you continue or not.
3. Perfectionism paralysis.
“If I can’t find the perfect system that will work forever, I might as well stick with what I have.” This is all-or-nothing thinking. Better is better, even if it’s not perfect.
4. Fear that the problem is you.
This is the deepest trap. If you change your system and it still doesn’t work, then you have to confront the possibility that maybe you’re the problem. So you don’t change anything, because at least then you can blame the method.
What This Signal Means and What to Do About It:
Resistance to changing a system is often emotional, not logical, and that’s completely normal. But here’s how to work through it:
1. Name the fear.
Ask yourself honestly: “What am I afraid will happen if I change this?” Sometimes just identifying the fear reduces its power.
2. Start small.
You don’t have to overhaul everything at once. Pick one element to modify and try it for a week. Low stakes, low risk.
3. Separate your worth from your system.
Your study methods are tools, not reflections of your intelligence or character. If a tool isn’t working, you get a different tool. That’s it.
5. Signal vs. Noise: Bad Day or Bad System?
Not every struggle means your system is awful. Sometimes you just have a bad week. Sometimes the material is genuinely harder. Sometimes life gets in the way.
The challenge is distinguishing between temporary friction (noise) and systematic failure (signal).
Students often abandon perfectly good systems after one rough experience, or they stick with failing systems because they blame external circumstances instead of recognizing a pattern.
It’s important to know the difference. Here’s how:
1. One bad week doesn’t mean your whole system is bad.
If your active recall study method worked great all semester and then you bombed one quiz during a particularly stressful week, that’s noise. Don’t overreact.
2. Consistent friction over 2-3 weeks means something needs attention.
If you’ve been struggling to execute your system, feeling frustrated with the results, or dreading your study sessions for multiple weeks in a row, that’s a signal. Pay attention to it.
3. The “good days/bad days” test.
Does your system work on your good days? If yes, the system is probably fine. You might just need to work on consistency or capacity (see Section 3). If your system doesn’t work even when you have time, energy, and focus, then your study system itself needs adjustment.
4. Consider seasonal and cyclical patterns.
Midterms and finals weeks are brutal for everyone. The week before spring break when you have three papers due is not the time to evaluate whether your planning system works. So look at patterns across normal weeks, not crisis weeks.
What This Signal Means and What to Do About It:
Trust patterns over individual instances. Some strategies:
1. Track your system for at least two weeks before making changes.
Keep a simple log: Did I follow my system today? How did it feel? What were the results? Patterns will emerge.
2. Distinguish between execution problems and design problems.
If you keep forgetting to use your planner, that’s an execution problem (maybe you need reminders or a different location for it). If you’re using your planner consistently but it’s not helping you manage your time, that’s a design problem (the system itself needs work).
3. Give new systems a fair trial.
When you do make changes, commit to trying them for at least two weeks before judging whether they work. New systems always feel awkward at first.
Final Notes: What To Do With This Information
If your study system stopped working, it’s normal and understandable. It’s just a sign that one or more of the following might be happening.
Your academic demands leveled up, but your system didn’t
You’re missing key skills your classes assume you have
You’re operating beyond capacity
You’re clinging to familiar failure out of fear
You’re reacting to noise instead of recognizing real signals
Recognizing which of these is happening is the critical first step. Once you know why your system stopped working, you can make informed decisions about what to do next.
Sometimes you need to tweak your existing system to work better for you. (If that’s where you are, read “How to Personalize Your Study Skills” for a step-by-step process.) Sometimes you need to reduce your commitments or increase support. And sometimes you need to acknowledge that a system that served you well has run its course, and it’s time to build something new.
Here’s what I want you to remember: no study system lasts forever. As you grow, as your classes change, as your life circumstances shift, your systems need to evolve too. That’s called evolution and adaptation, and it’s not only part of life but it literally is life.
The students who succeed aren’t the ones who find the perfect system and never change it; they’re the ones who notice when something stops working and have the courage to do something about it.
Success! Now check your email to confirm your subscription.