As financial pressures continue to bear down on higher education institutions across the UK, there is a visible impact on higher education staff, as resources shrink, portfolios are rationalised, and redundancy programmes are implemented. These are definitively tough times for the sector and its people.
One way this plays out is in the industrial relations landscape, with unions balloting for industrial action, as well as, on some specific issues, advancing joint work with employers.
But there is a wider, arguably more nuanced, lens to bring to bear, about how the current circumstances are reshaping staff experiences of working in higher education, and what options are available to those with responsibility for leading and supporting higher education staff.
When the Wonkhe team came up with the idea of running a national survey for higher education staff we knew from the outset that we would not be able to produce definitive statements about “the HE staff experience” derived from a representative sample of responses. There is no consensus over how you would define such a sample in any case.
The best national dataset that exists is probably found in UCEA publications that combine institutional staff experience survey datasets at scale – one published in 2024 titled “What’s it really like to work in HE?” and one in May this year diving into some of the reported differences between academic and professional staff, “A tale of two perspectives: bridging the gap in HE EX.”
Instead we wanted to, firstly, ask some of the questions that might not get asked in institutional staff surveys – things like, how staff feel about their institution’s capacity to handle change, or the relative importance of different potential motivating factors for working in HE, or, baldly, how institutional cost-cutting is affecting individuals. And secondly, as best we can, to draw out some insight that’s focused on supporting constructive conversations within institutions about sustaining the higher education community during challenging times.
We’ll be reporting on three key areas:
- “Quality of work” – discussed further below
- Professional motivations, the relative importance of different motivators for our sample group, and the gap between the level of importance afforded key motivators and the extent to which respondents believe they actually get to experience these in their roles – DK has tackled that subject and you can read about his findings here
- Views on institutional change capability – coming soon!
We’ve not covered absolutely everything in this tranche of reporting – partly because of time pressures, and partly because of format constraints. We have a fair bit of qualitative data to dive into, as well as the third area of investigation on institutional change capability all still to come – watch this space.
The methodology and demographics bit
We promoted the survey via our mailing list (around 60,000 subscribers) during July and August 2025, yielding a total of 4,757 responses. We asked a whole range of questions that we hoped could help us make meaningful comparisons within our sample – including on things like nationality, and type and location of institutions – but only some of those questions netted enough positive responses to allow us to compare two or more good-sized groups.
Our working assumption is that if there was a group of around 500 or more who share a particular characteristic it is reasonable to compare their responses to the group of respondents who did not have that particular characteristic. We have conducted analysis of the following subgroups:
- Career stage: Early career (n=686), mid career (n=1,304), and late career (n=2,703)
- Those with an academic contract (n=1,110) and those with a non-academic contract (n=3,394) – excluding some other kinds of roles/contracts
- Time in higher education: five years or fewer (n=908); 6-10 years (n=981); 11-20 years (n=1,517) and more than 20 years (n=1,333)
- Working arrangements: on-site (n=988); working from home or remotely (n=475); and flexible/hybrid (n=3,268)
- Leadership role: respondents who said they have formal management or leadership responsibility in their current role for projects, programmes, resources, or people (n=3,506), and those who did not (n=1,214)
And we also looked at the following identity characteristics:
- Gender: men (n=1,386) and women (n=3,271)
- Sexuality: those who identified as gay, lesbian, bisexual or queer (n=654) and those who did not (n=4,093)
- Ethnicity: those who identified as being of a minoritised ethnicity (n=247) and those who did not (n=4,444)
- Disability: those who identified as being disabled (n=478) and those who did not (n=4,269)
In one case – that of respondents who identified as being of a minoritised ethnicity – our sample didn’t meet the threshold for wholly robust analysis, but we found some differences in reported experience, which we think is worth reporting given what we already know about this group of staff, and would caution that these findings should be viewed as indicative rather than definitive.
In some cases we have combined subgroups to make larger groups – for example we’ve grouped various academic roles together to compare with roles on other kinds of contracts. In others we’ve ignored some very small (usually n=3 and below) groups to make for a more readable chart; for this reason we don’t often show all responses. And although our response rates are high you don’t have to refine things much to get some pretty low numbers, so we’ve not looked at intersections between groups.
We have reported where we found what we considered to be a meaningful difference in response – a minimum of four percentage points difference.
The financial context
88 per cent of respondents said their institution has taken material steps to reduce costs in the last 12 months, offering a background context for answers to the wider survey and the assurance that the thing we are looking at is definitely staff views against a backdrop of change.
51.6 per cent said they personally had been negatively affected by cost reduction measures, while 41.9 per cent said the personal impact was neutral. This suggests that while cost reduction may be widely viewed as negative, that experience or the views that arise from it may not be universal.
Of those that said they had been negatively affected we found no meaningful differences among our various comparator groups. Leaders and those later in their career, were as likely to report negative impacts as those without leadership responsibilities or earlier in their career, suggesting that there is little mileage in making assumptions about who is more likely to be negatively impacted – though of course we did not try to measure the scale of the impact, and we’re mindful we were talking to people who had not lost their jobs as a result of cost-saving measures.
The one exception was between those on academic contracts, of whom nearly two third (65.3 per cent) reported negative impacts, and those on non-academic contracts, of whom the number reporting negative impact was closer to half (47.4 per cent). This difference gives important context for the wider findings, in which those on academic contracts are consistently more likely to offer a negative perspective than those on non-academic contracts across a range of questions. This tallies to some degree with the national picture explored in UCEA’s “Bridging the gap” report in which academics were more likely to report challenges with workload, work-life balance, and reward and recognition, than professional staff – though higher levels of work satisfaction.
Regretting and recommending HE
We asked whether, taking into account what is known about other available career paths, whether respondents feel that choosing to work in HE was the right decision for them – two thirds said yes (66.9 per cent) while 23.8 per cent were unsure. Only 9 per cent said no.
Those approaching the end of their career were more likely to agree (74.3 per cent) compared to those mid-career (65 per cent) or early career (61.2 per cent). Those with leadership responsibilities were also slightly more likely to agree, at 68.2 per cent, compared to 62.3 per cent for those without leadership responsibilities.
Those on academic contracts were slightly less likely to agree, at 60.8 per cent compared to 68.9 per cent for those on non-academic contracts.
However, the real divide opens up when we looked at responses to our follow up question: whether respondents would recommend a career in higher education to someone they cared about who was seeking their advice. A much smaller proportion of our sample agreed they would recommend a career in HE (42.2 per cent), with much higher rates of “unsure” (32.1 per cent) and “no” (24.5 per cent) – most likely reflecting the impact of current challenges as compared to people’s longer-term lived experience.
For the recommend question, the career-stage trend reverses, with those approaching the end of their careers less likely to say they would recommend a career in HE (39.2 per cent) compared to 41.6 per cent for those mid-career and 50.4 per cent for early career respondents.
There was a substantial difference by role: only 25.7 per cent of those on academic contracts would recommend a career in HE, compared to 46.9 per cent of those on non-academic contracts.
We did not find any differences by gender, ethnicity, disability, or sexuality on either confidence in the decision to work in HE or willingness to recommend it as a career.
Quality of work
One of the great things about higher education as an employment sector is that there are lots of ways to be employed in it and lots of different types of jobs. What one person values about their role might be quite different from what another person appreciates – and the same for the perceived downsides of any given role.
So rather than trying to drill down into people’s reported experiences based on our own probably biased views about what “good work” looks and feels like, we turned to the idea of “quality of work” as a guiding framework to look at respondents’ experiences and perceptions. We asked 16 questions in total derived from this 2018 Carnegie UK-RSA initiative on measuring job quality in the UK which proposes seven distinct dimensions of work quality, including pay and conditions, safety and wellbeing, job design, social support, voice, and work-life balance.
We also kept in mind that, while support, safety and wellbeing at work are foundational conditions for success, so is effective performance management and the opportunity to apply your skills. In the spirit of Maslow’s hierarchy of needs we clustered our questions broadly into four areas: safety, security, and pay/conditions; the balance between support and challenge; relationships with colleagues; and “self-actualisation” incorporating things like autonomy and meaningfulness.
For each question, respondents were offered a choice of Strongly disagree, Disagree, Agree, and Strongly agree. Here we report overall levels of agreement (ie Agree and Strongly Agree)
You can see the full findings for all our comparator groups in the visualisation below.
[Full screen]
Headlines on quality of work and interaction with willingness to recommend
You can see all the workings out below where I’ve gone through the results line by line and reported all the variations we could see, but the TL;DR version is that the quality dimensions that jump out as being experienced comparatively positively are physical safety, good working relationships with colleagues, and meaningfulness of work. Two key areas that emerge as being experienced comparatively negatively are feeling the organisation takes your wellbeing seriously, and opportunities for progression – the level of agreement is startlingly low for the latter.
We compared the various quality dimensions against whether people would recommend a career in higher education for the whole sample and found that across every question there was a direct correlation between a positive response and likelihood to recommend a career in HE – and the inverse for negative responses. We think that means we’re asking meaningful questions – though we’ve not been able to build a regression model to test which quality questions are making the largest contribution to the recommend question (which makes us sad).
[Full screen]
Going through the various comparator groups for the quality of work questions we find that there are three core “at risk” groups – one of which is respondents of a minorised ethnicity, which comes with caveats regarding sample size. Another is those on academic contracts, and the third is disabled respondents. These groups did not consistently respond more negatively to every question on quality of work, but we did find enough differentiation to make it worth raising a flag.
So to try to see whether we could find some core drivers for these “at risk” groups, we plotted the response to the “recommend” question against the responses to the quality questions just for these groups. At this point the samples for disabled and minoritised ethnic responses become just too small to draw conclusions – for example, under 100 respondents who identified as being of a minoritised ethnicity said they would not recommend a career in HE.
However, over 400 of those on academic contracts said they would not recommend a career in HE, so we compared the answers of that group to those of respondents on non-academic contracts who also would not recommend a career in HE (just shy of 700 respondents). Interestingly for a number of the quality questions there was no differentiation in response between the groups, but there was noticeable difference for “reasonable level of control over work-life balance”, “able to access support with my work when I need it”, and “opportunities to share my opinion” – in the sense that among the group that would not recommend HE the academic cohort were more likely to give negative responses to these questions, giving a modest indication of possible priority areas for intervention.
We also found that those who had worked in higher education for five years or fewer were frequently more likely to report agreement with our various propositions about quality work. While there’s clearly some overlap with those early in their career they are not entirely the same group – some may have entered HE from other sectors or industries – though early career respondents do also seem to emerge as having a slightly more positive view as well, including on areas like emotional safety, and wellbeing.
Safety, security and pay and conditions
The four statements we proposed on this theme were:
- I feel reasonably secure in my job
- I am satisfied with the pay and any additional benefits I receive
- I feel physically safe at work
- I feel emotionally safe at work
On job security, overall two thirds (66.3 per cent) of our sample agreed or strongly agreed that they feel reasonably secure in their job. Those on academic contracts reported lower levels of agreement (57.8 per cent). Those who said they had been employed in higher education for five years or fewer reported higher levels of agreement (71.4 per cent). Respondents who identified as disabled reported slightly lower levels of agreement (61.9 per cent).
On satisfaction with pay, conditions and additional benefits, overall 63.8 per cent of respondents agreed or strongly agreed that they were satisfied. Those on academic contracts reported lower levels of agreement (56.3 per cent). Those who identified as having a minoritised ethnicity had the lowest levels of agreement of all our various comparators (53.1 per cent), and were twice as likely to strongly disagree that they were satisfied with pay and benefits than those from non-minoritised ethnicities (15.2 per cent compared to 7.9 per cent). Those who identified as disabled had lower levels of agreement (54.6 per cent agreement) compared to those who did not consider themselves disabled (64.9 per cent agreement)
On physical safety, the vast majority of respondents (95.8 per cent) agreed or strongly agreed they feel physically safe at work with very little variation across our comparator groups. While the overall agreement was similar between men and women, notably men were more likely to register strong agreement (66.3 per cent) than women (51.9 per cent).
On emotional safety the picture is more varied. Overall 72 per cent agreed or strongly agreed they feel emotionally safe at work. Those who reported being earlier in their career reported higher levels of agreement (78.6 per cent), as did those who reported having worked in the HE sector for five years or fewer (78.6 per cent). Those with academic contracts reported lower levels of agreement (61.62). Those who identified as having a minoritised ethnicity had lower levels of agreement (62.7 per cent) and were more than twice as likely to strongly disagree they feel emotionally safe at work than those who are not minoritised (14.2 per cent compared to 6.1 per cent).
Balance, challenge, and performance
The four statements we proposed on this theme were:
- The work I do makes appropriate use of my skills and knowledge
- I have a reasonable level of control over my work-life balance
- My organisation demonstrates that it takes my wellbeing seriously
- My organisation demonstrates that it takes my performance seriously
On using skills and knowledge 79.2 per cent of our sample agreed or strongly agreed that their work makes appropriate use of their skills and knowledge. There was very little variation between comparator groups – the one group that showed a modest difference was those who reported being disabled, whose agreement levels were slightly lower at 75.3 per cent.
On control over work-life balance, 80.7 per cent of our sample agreed or strongly agreed they have a “reasonable” level of control. Those who had worked in higher education for five years or fewer were more likely to agree (87.2 per cent). 86.5 per cent of those who work from home agreed, compared to 74.4 per cent of those who work on campus or onsite, and 81.7 per cent of those who have hybrid or flexible working arrangements. Those who reported having leadership responsibilities had lower levels of agreement (78.9 per cent) compared to those who did not (85.9 per cent).
The biggest difference was between those on academic contracts (66 per cent agreement) and those on non-academic contracts (85.3 per cent agreement). There were also slightly lower scores for disabled respondents (74.7 per cent compared to 81.2 per cent for non-disabled respondents) and for minoritised ethnicities (76.6 per cent compared to 81 per cent for non-minoritised ethnicities).
On wellbeing, 57.8 per cent of our sample agreed or strongly agreed that their organisation demonstrates that it takes their wellbeing seriously. This was higher for early-career respondents – 60 per cent agreement compared to 57.9 per cent for those in mid-career, and 55.5 per cent for those approaching the end of their career. Agreement was higher for those with five years or fewer in higher education at 68.4 per cent agreement, compared with 54.5 per cent for those with more than 20 years’ experience.
Those on academic contracts were substantially less likely to agree with only 39.7 per cent agreement that their organisation demonstrates that it takes their wellbeing seriously. Disabled respondents were also much less likely to agree than non-disabled respondents, at 47.7 per cent and 59 per cent respectively. Those working from home reported slightly lower levels of agreement, at 52.6 per cent.
On performance, 63.1 per cent of our sample reported that their organisation demonstrates that it takes their performance seriously. This was slightly higher for those who had five years or fewer in higher education, at 69.6 per cent. Again, there was a difference between those on academic contracts with 57.8 per cent agreement and those on non-academic contracts, with 64 per cent agreement. Disabled respondents were slightly less likely to agree (58 per cent agreement) than non-disabled (63.8 per cent agreement).
Relationships with colleagues
The four statements we proposed on this theme were:
- I am able to access support with my work when I need it
- I am given sufficient opportunities to share my opinion on matters that affect my work
- For the most part I have a good working relationship with my colleagues
- I generally trust that the people who work here are doing the right things
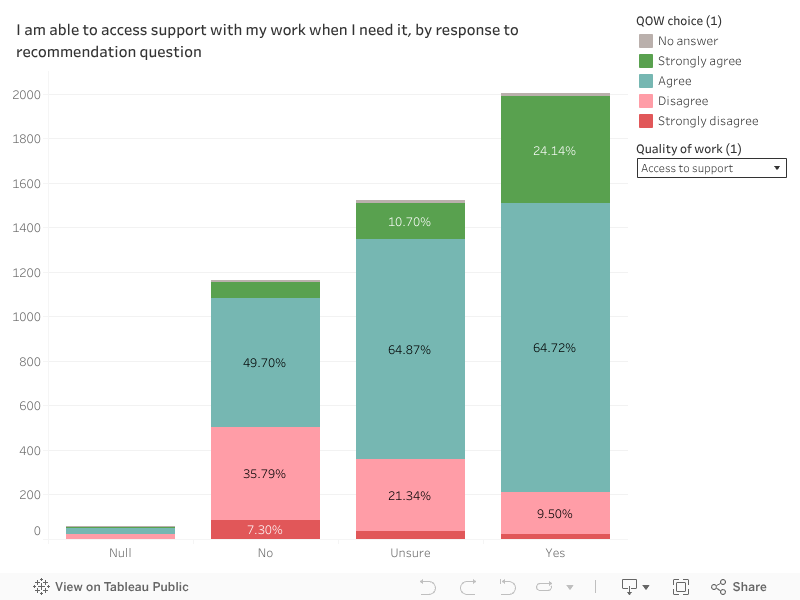
On accessing support, 76.2 per cent of our sample agreed they are able to access support when they need it. There was higher agreement among those early in their career at 81.3 per cent, and similarly among those who had worked five years or fewer in HE, at 82.8 per cent. There was lower agreement among those on academic contracts: 62.3 per cent agreement versus 80.5 per cent for those on non-academic contracts. Those from a minoritised ethnicity had lower agreement at 70.6 per cent, as did disabled respondents at 67.4 per cent.
On opportunities to share opinion, 70.4 per cent of our sample agreed or strongly agreed they were given sufficient opportunities to share their opinion on matters that affect their work. There was a small difference between those who held a leadership role and those who did not, at 71.9 per cent and 66 per cent agreement respectively. Again, those on academic contracts had lower levels of agreement, at 58.2 per cent compared to 73.9 per cent for those on non-academic contracts. Disabled staff also had lower agreement at 60.9 per cent.
On working relationships, cheeringly, 96.1 per cent of our sample agreed or strongly agreed they have good working relationships with their colleagues. While this held true overall across all our comparator groups regardless of leadership roles, working location, personal characteristics or any other factor, notably those of a minoritised ethnicity strongly agreed at a lower rate than those who did not identity as being from a minoritised ethnicity (39.6 per cent strong agreement compared to 48.3 per cent).
On trust, 70.8 per cent of our sample agreed or strongly agreed that they generally trust the people they work with are doing the right things. This was very slightly lower among those who work from home or remotely, at 65.9 per cent. Agreement was lower among those on an academic contract, at 61.6 per cent, compared to 73.4 per cent of those on a non-academic contract. Agreement was also lower among disabled respondents, at 63.8 per cent.
“Self-actualisation”
The four statements we proposed on this theme were:
- My current job fits with my future career plans and aspirations
- I am comfortable with the level of autonomy I have in my job
- There are sufficient opportunities for progression from this job
- The work I do in my job is meaningful
On career plans, 76.1 per cent of our sample agreed or strongly agreed that their current job fits with their future career plans and aspirations. Those who said they work from home or remotely had slightly lower levels of agreement at 69.3 per cent. Those who said they do not have any kind of leadership role had slightly lower levels of agreement at 69.4 per cent.
On autonomy, 82.5 per cent of our sample agreed or strongly agreed they were comfortable with the level of autonomy they have in their job. Those with an academic contract had very slightly lower levels of agreement at 77.9, compared to 83.8 per cent agreement among those on non-academic contracts. Those of a minoritised ethnicity had lower levels of agreement at 73.9 per cent, as did disabled respondents, at 75.9 per cent agreement.
On progression, a startling 29.5 per cent agreed or strongly agreed that there are sufficient opportunities for progression from their current position. There was a modest difference between those with leadership roles, 31.1 per cent of whom agreed, compared to 25 per cent of those without a leadership role. Those on academic contracts had higher levels of agreement at 38.5 per cent, compared to 26.8 per cent of those on non-academic contracts.
On meaningful work, 86.1 per cent of our sample agreed or strongly agreed that the work they do in their job is meaningful. Those who work from home or remotely had very slightly lower levels of agreement at 77.9 per cent but otherwise this held true across all our comparator groups.
Aspiration to lead and preparedness to lead
We asked about whether respondents aspire to take on or further develop a leadership role in higher education, and if so, whether they are confident they know what a path to leadership in higher education involves in terms of support and professional development. These questions are particularly relevant given the generally negative view about opportunities to progress held by our survey respondents.
[Full screen]
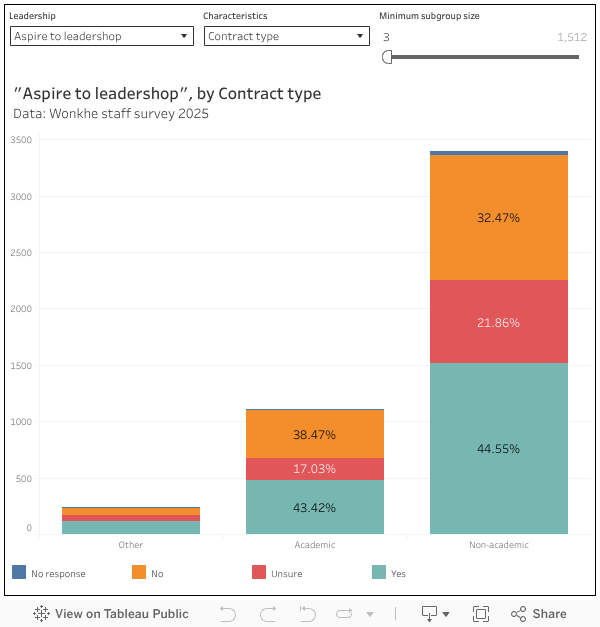
Overall, 44.5 per cent of our sample said they aspire to take on or further develop a leadership role. Curiously, this was only slightly higher for those who already have some level of leadership responsibility, at 48.3 per cent. This can be explained to some degree by differentiation by career stage: 58.8 per cent of early career respondents aspired to take on or develop leadership roles, as did 50.9 per cent of mid-career respondents.
Aspiration to lead was higher among those identifying as lesbian, gay, or bisexual at 52.6 per cent compared to 43.2 per cent for those who did not. Aspirations were also higher among respondents of a minoritised ethnicity, at 54.5 per cent, compared to 43.8 per cent among those not of a minoritised ethnicity.
We also asked respondents whether they are confident they know what a path to leadership involves in terms of support and professional development, where we found some important variations. Confidence about pathways to leadership was lower among early career respondents, at 22.8 per cent agreement, and even mid-career respondents confidence was lower than the numbers reporting they aspire to leadership, at 36.6 per cent.
While there was no difference in aspiration between respondents on academic contracts and those on non-academic contracts, those on academic contracts were more likely to say they are confident they know what a path to leadership involves, at 50.3 per cent compared to 34.8 per cent.
While there was no difference in aspiration between men and women respondents, women were slightly less likely than men to report confidence in knowing about the path to leadership, at 37.5 per cent compared to 42 per cent. Those who identify as lesbian, gay or bisexual, those of a minoritised ethnicity, and disabled respondents were also slightly less likely than their comparator groups to express confidence, despite having expressed aspiration to lead at a higher rate.
These findings around demographic difference suggest that there remains some work to be done to make leadership pathways visible and inclusive to all.
We’ll be picking up the conversation about sustaining higher education community during tough times at The Festival of Higher Education in November. It’s not too late to get your ticket – find out more here.